你是否曾幻想過,AI 不再只是個聊天機器人,而能像得力助手一樣主動幫你完成複雜任務?Advantech 最新研發的 GenAI Studio 搭配 Google 全新 Gemma 4 大腦,讓這個夢想正式成真!本篇將帶你走進我們的本地自主代理實驗室,揭示這波 AI 革命如何開啟個人化智能的全新時代。
回顧未來:AI 從聊天小幫手晉升數位員工 #
想像一下,來到 2026 年,AI 已不再侷限於「對話框」裡回答你的問題。現今的 AI 已能主動規劃流程、執行電腦操作,甚至幫你自動處理各種應用程式和線上服務!這一切的關鍵,就是自主代理(Autonomous Agents)技術的興起。特別是 OpenClaw 框架的問世,讓 AI 正式從「聊天時代」跨入「代理時代」,真正成為你的數位左右手。
雲端 AI 的隱形枷鎖:隱私、成本、穩定性三重挑戰 #
雖然雲端 AI 很方便,但當 AI 代理開始處理敏感數據、執行多步驟任務時,三大痛點浮現:
- 隱私與安全:重要資料需經雲端中轉,資訊安全令人擔憂。
- 高昂成本:複雜任務會消耗大量運算資源,API 費用飆升。
- 穩定性焦慮:網路斷線就可能導致任務失敗,影響生產力。
這些問題迫使我們思考:能否打造一套智慧又完全自主的本地 AI 代理系統?
創新突破:Gemma 4—為本地代理量身打造的超級 AI 大腦 #
2026 年 4 月,Google 推出 Gemma 4,這不只是一款開源模型,更是現今最適合本地 AI 代理的「超級大腦」!Gemma 4 針對邏輯推理、函式呼叫(Function Calling)進行專屬優化,與 OpenClaw 框架天作之合。
Gemma 4 系列核心規格一覽 #
| 型號 | 參數量 | 上下文長度 | 多模態支援 | 特色 |
|---|---|---|---|---|
| E2B | 23 億 | 128k | 文字、圖片、音訊 | 輕量高速 |
| E4B | 45 億 | 128k | 文字、圖片、音訊 | 終端裝置首選 |
| 26B A4B | 252 億 | 256k | 文字、圖片 | MoE 架構(效能超強) |
| 31B | 307 億 | 256k | 文字、圖片 | 邏輯推理旗艦 |
Gemma 4 的三大亮點 #
- 原生多模態能力:能讀懂文字、圖片,甚至音訊,讓 AI 代理具備「視覺」和「聽覺」。
- 結構化輸出:支援 JSON 格式,與 OpenClaw 指令高度協作。
- 彈性授權:Apache 2.0,企業深度整合無後顧之憂。
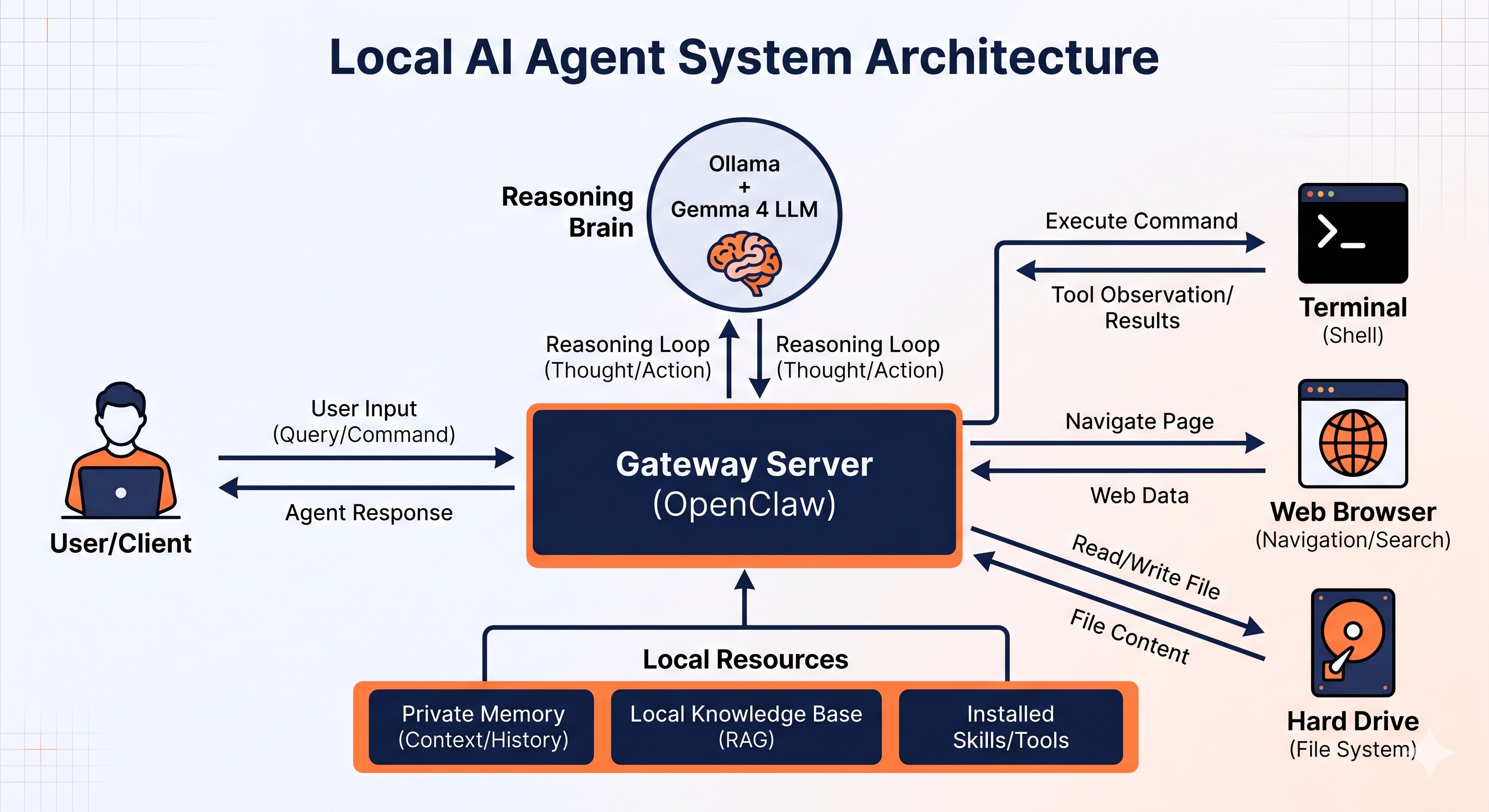
三位一體架構:GenAI Studio x Gemma 4 x OpenClaw #
為了讓本地代理運作無縫流暢,我們打造了三位一體的架構:
- GenAI Studio 1.3(推論引擎):以最佳化 Ollama 核心為基礎,針對 NVIDIA RTX 50/60 系列 GPU 深度優化,讓 Gemma 4 跑在本地又快又穩。
- Gemma 4(決策大腦):分析指令、推理思考、規劃步驟,像軍師一樣做決策。
- OpenClaw(執行系統):包含規劃器與執行器,讓 AI 代理真正「動手做事」。
最大特色:所有資料完全封閉於本地硬體,無需連網!隱私無死角,延遲超低,打造專屬私有 AI 實驗室。
一步到位!打造你的本地 AI 代理實驗室 #
跟著我們的腳步,輕鬆啟動本地 AI 代理系統:
1. 安裝 GenAI Studio 1.3 與 Gemma 4 #
- 一鍵安裝:快速完成環境準備。
- 匯入模型:
cd ~/Advantech/GenAI-Studio ./ollama-model import gemma4:26b --from-registry建議:搭配 RTX 5090 顯卡,推薦選用 26B (MoE) 版本,速度與邏輯完美平衡。
2. 部署 OpenClaw 框架 #
只需三步,OpenClaw 與 GenAI Studio 就能完美對接:
curl -fsSL https://openclaw.ai/install.sh | bashopenclaw onboard(過程中連接 GenAI Studio 本地 API 端口)openclaw dashboard(開啟管理介面)
3. 硬體實測:AIR-420 + RTX 5090 效能全揭露 #
我們在 AIR-420 平台搭配 NVIDIA RTX 5090 做了壓力測試,以下是 Gemma 4 兩大版本的實測數據:
| 指標 | Gemma 4 26B (MoE) | Gemma 4 31B (Dense) |
|---|---|---|
| 總執行耗時 | 741.99 ms | 1.53 s |
| 模型載入耗時 | 161.24 ms | 179.29 ms |
| 生成速率 | 211.42 tokens/s | 67.84 tokens/s |
解讀重點:Gemma 4 26B(MoE 架構)在 RTX 5090 上每秒可生成超過 200 tokens,反應超快,特別適合需要即時回應的代理任務。而 31B 版本則在邏輯推理上更勝一籌,適用於更複雜場景。
小撇步大提升:讓你的本地 AI 代理發揮 120% 實力 #
- 依顯卡 VRAM 選型:大顯存(如 RTX 6000)建議選 31B 旗艦版,長流程任務超穩定。追求速度則首選 26B A4B(MoE 架構)。
- 溫度值設定:執行 Agent 任務時,將 Temperature 設定為 0.2 或更低,確保產出結構穩定、錯誤率低。
- 適當上下文視窗:雖 Gemma 4 支援 256k,上下文建議控制在 32k~64k,兼顧記憶力與速度。
- 量化選擇:預設已高品質,若追求極致精度,可選更高位元版本,精細解析模糊指令。
Advantech 創新實力,帶你開啟私有 AGI 新紀元! #
建構屬於自己的本地 AI 代理,不只是技術突破,更是數位自主權的實現。當你親眼見證 Gemma 4 在 GenAI Studio 驅動下高速思考,OpenClaw 自如操作各種工具,那種「完全掌控、絕對隱私」的安全感,是任何雲端服務難以企及的。
這場本地 AI 革命才剛開始——Advantech 將持續深耕 AI 研發、精進產品整合,陪你一同探索 AGI(通用人工智慧)的無限可能。馬上下載 GenAI Studio,讓你的電腦進化為具備思考與行動力的超級助理,勇敢迎接個人化 AI 時代的到來!