Unsloth LoRA:AI微調的「超省力」新選擇 #
在AI發展的世界裡,「大」一直是主流——更大模型、更複雜運算,但也意味著更高成本與資源消耗。LoRA微調技術正是破解這個困境的關鍵!它只需調整模型中極少數的參數,就能讓AI快速適應新任務,省時又省力。而Unsloth框架,更是將這項技術推向新高峰,讓微調過程變得更快、更穩定、更彈性。
應用場景超廣泛:
無論是客服對話、智慧醫療、金融諮詢、還是產業知識問答,只要需要AI根據專屬資料「量身訂做」表現,LoRA微調就是你最佳夥伴!
關鍵參數大公開:微調效能、資源與表現一手掌握 #
你以為微調只要按下「開始」鍵就好?其實背後有許多「眉角」!來看看我們這次實驗的參數設計重點,讓你快速上手、事半功倍:
1. 基礎選項 #
- 批次大小(Batch Size) #
- 一次處理多少資料?Unsloth優化記憶體使用,允許你設定更大的Batch Size,訓練更穩定、效率更高。
- 最大序列長度(Maximum Sequence Length) #
- 一次能「看」多長的文本?Unsloth讓處理長篇輸入更無壓力,讓模型不再「記憶力短缺」。
- 學習率(Learning Rate) #
- 每一步調整多大?LoRA可設定比傳統全參數微調略高的學習率(如$2e-4$到$1e-3$),加速模型學習,記得避免太高導致不穩定。
- 訓練週期(Epoch) #
- 來回學習幾輪?LoRA參數少,訓練速度快,通常不用太多Epoch,但還是要小心過擬合,建議搭配驗證集監控與早停機制。
2. 進階選項——LoRA專屬參數 #
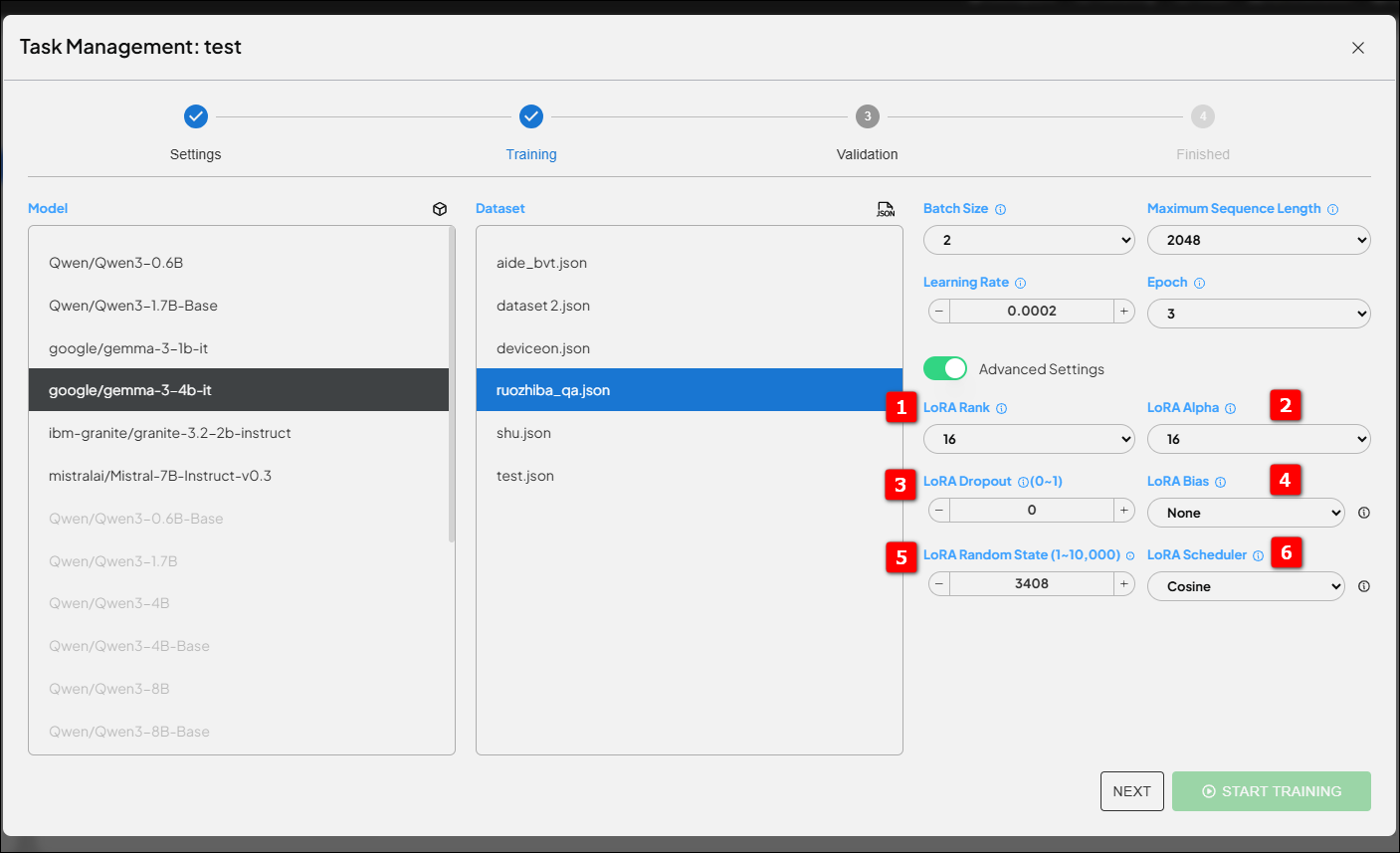
- 1. LoRA Rank (r) #
- 決定適應層的「容量」。Rank越大,模型越靈活但耗資源;Rank越小,輕量高效但學習能力有限。建議起步值:16、32、64。
- 2. LoRA Alpha ($\alpha$) #
- 調整學習幅度,影響學習率與穩定性。一般建議$\alpha = 2 \times \text{Rank}$,隨Rank成比例調整,確保模型學習不過猛也不太慢。
- 3. LoRA Dropout #
- 適度「隨機禁用」部分參數,讓模型不會死記訓練資料。建議值0.1,資料少時可略高,資料多時可調低。
- 4. LoRA Bias #
- 是否調整模型偏置?多數情況選None即可,保留LoRA設計的精簡特點。
- 5. LoRA Random State #
- 需要每次結果一致?固定一個數字!想多方嘗試?隨機選號探索更佳解。
- 6. LoRA Scheduler #
- 學習率如何隨訓練進度變化?推薦Linear(線性遞減)、Cosine(餘弦衰減)、Constant with Warmup(先預熱後恆定)等排程,助力模型穩定收斂。
不同資料集,如何調整LoRA參數?Advantech工程師實戰建議 #
小規模資料集(數百~數千樣本) #
- 重點:防止過擬合!
- LoRA Rank:8、16
- Dropout:0.1~0.2
- 學習率:$1e-4$~$3e-4$
- Epoch:可多,但一定要驗證集+早停
大規模資料集(數萬~百萬樣本) #
- 重點:訓練效率與表現!
- LoRA Rank:32、64甚至128
- Dropout:0.05或0
- 學習率:$3e-4$~$5e-4$
- Epoch:1~3,搭配學習率排程器
文本長度變化大 #
- 重點:靈活調整序列長度與Batch Size!
- Sequence Length:參考資料分佈90%或95%分位點(如1024、2048)
- Batch Size:視記憶體而定,長文本時可適當縮小
專業/特定領域資料集 #
- 重點:給模型足夠表達力學新知!
- LoRA Rank:32或64
- 學習率:如有收斂困難可再調低
Advantech的技術創新實力,讓AI更懂你! #
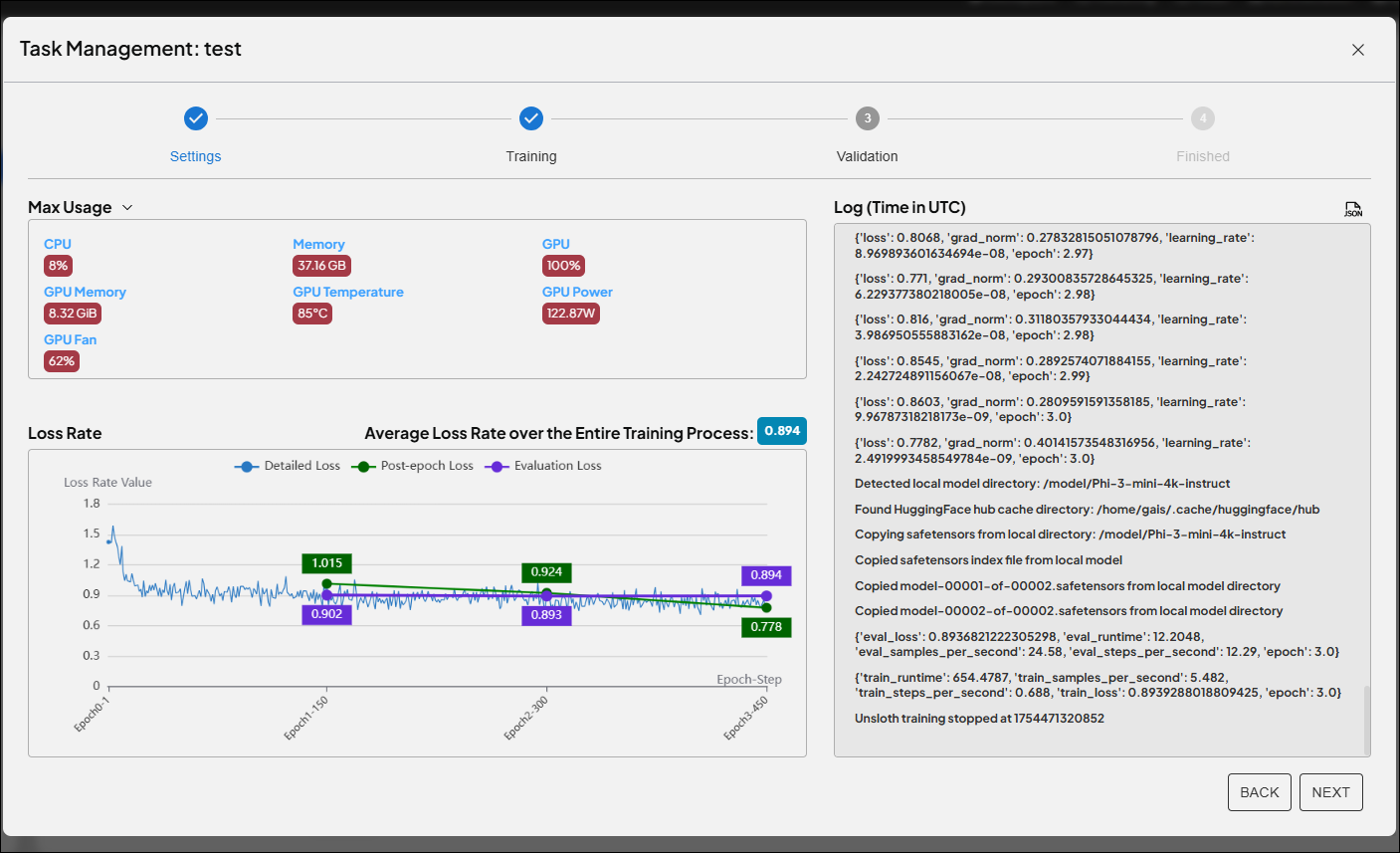
這次實驗證明,Unsloth LoRA不僅能大幅提升AI微調效率,還能靈活因應各種資料規模與產業需求。關鍵參數如LoRA Rank與Alpha的細緻調整,是釋放AI潛力的秘密武器。更重要的是,Advantech團隊持續投入AI核心技術研發,推動產業數位轉型與智能升級。
未來,我們將持續探索更高效、更聰明的微調技術,攜手客戶打造專屬的智慧應用,讓AI真正落地、創造價值。如果你也對AI微調、智慧應用有興趣,歡迎隨時與我們交流,下一個創新突破,或許就是你我共同的故事!
小結Tips:
- LoRA微調=效率升級,Unsloth框架讓你資源省、省、省!
- 參數設定有學問,實驗+監控才有最理想成效。
- Advantech持續創新,助你AI應用搶先一步!
(想深入交流或體驗更多技術細節,請聯絡Advantech專業團隊!)