為什麼要在 Jetson Orin 上跑 AI 大模型? #
隨著 AI 越來越普及,邊緣運算需求也持續升溫。不論是智慧製造、零售、交通,還是醫療,現場即時推論、大量數據處理都變得至關重要。NVIDIA Jetson Orin 平台,以高效能、低功耗著稱,特別適合部署先進 AI 應用。但要讓像 DeepSeek-R1 這樣的大型語言模型在邊緣設備順暢運作,背後其實有不少挑戰。本次實驗,就是為了驗證與優化這個流程,讓 AI 真正走進現場!
實驗平台與技術簡介 #
主角登場:Advantech Jetson Orin 家族 #
這次測試採用了兩款主力平台:
- EPC-R7300:配備 NVIDIA Jetson Orin Nano-Super 8GB,搭載 128GB NVMe SSD,系統為 JetPack 6.1。
- AIR-030:配備 NVIDIA Jetson Orin AGX 32GB/64GB,搭載 64GB NVMe SSD,系統為 JetPack 6.0。
不論你是想在輕量級設備上做推論,還是需要強大效能支援更大模型,這兩款平台都能滿足不同場景的需求!
支援模型一覽 #
- EPC-R7300:支援 DeepSeek R1 Qwen-1.5B、Qwen-7B、Llama-8B
- AIR-030:額外支援 DeepSeek R1 Qwen-32B、Llama-70B
這代表,從小型到超大型 LLM 模型,都能在 Advantech 平台上開箱即用!
實驗流程大公開:讓 AI 跑起來就是這麼簡單! #
想像一下,你只需要幾個步驟,就能在自己的設備上實現自然語言對話、數學推理、甚至各種專業應用。以下為完整實驗步驟,無論你是工程師還是業務夥伴,都能輕鬆上手!
1. 安裝 Docker 與 Jetson-Containers #
跟著官方步驟快速安裝,詳細說明可參考: NVIDIA Jetson AI Lab 安裝說明
安裝 jetson-containers:
cd /home/ubuntu/Downloads
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
2. 關閉系統通知,讓實驗更專注 #
- 關閉彈出式警告,避免測試中斷

- 安裝 dconf-editor
sudo apt update sudo apt install dconf-editor - 使用 dconf-editor 進入 /org/gnome/desktop/notifications/,依圖示關閉通知
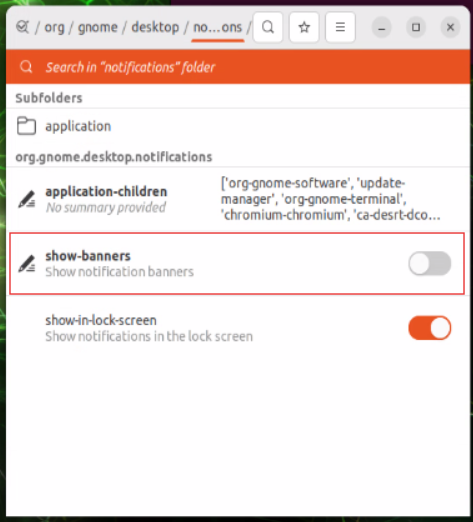
3. 啟動 Ollama 與 Open WebUI #
啟動 Ollama Docker 容器 #
jetson-containers run --name ollama dustynv/ollama:r36.4.0
執行後請保持命令視窗開啟。
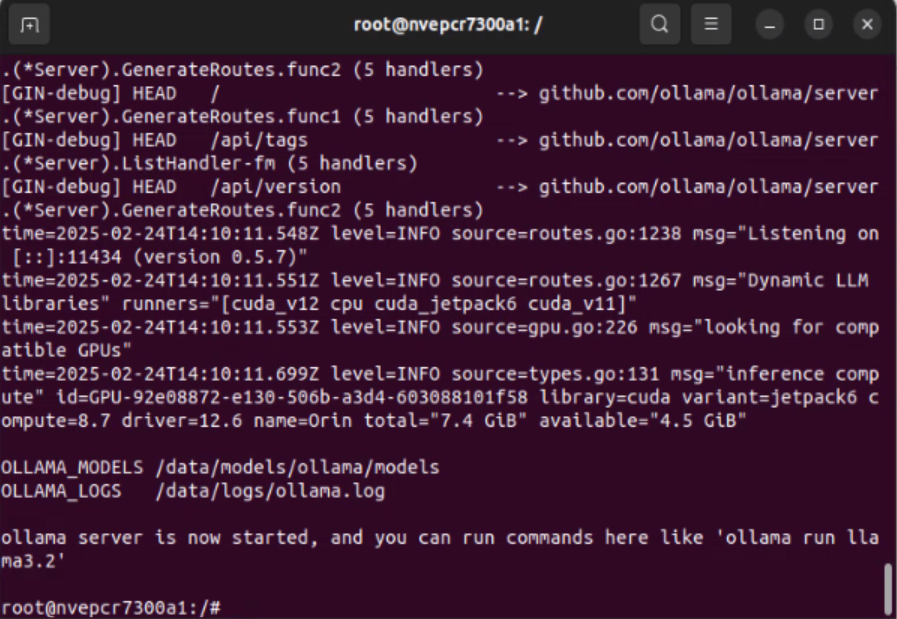
啟動 Open WebUI 讓瀏覽器連接 #
在新命令視窗執行:
docker run -it --rm --network=host -e WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
同樣保持視窗開啟。
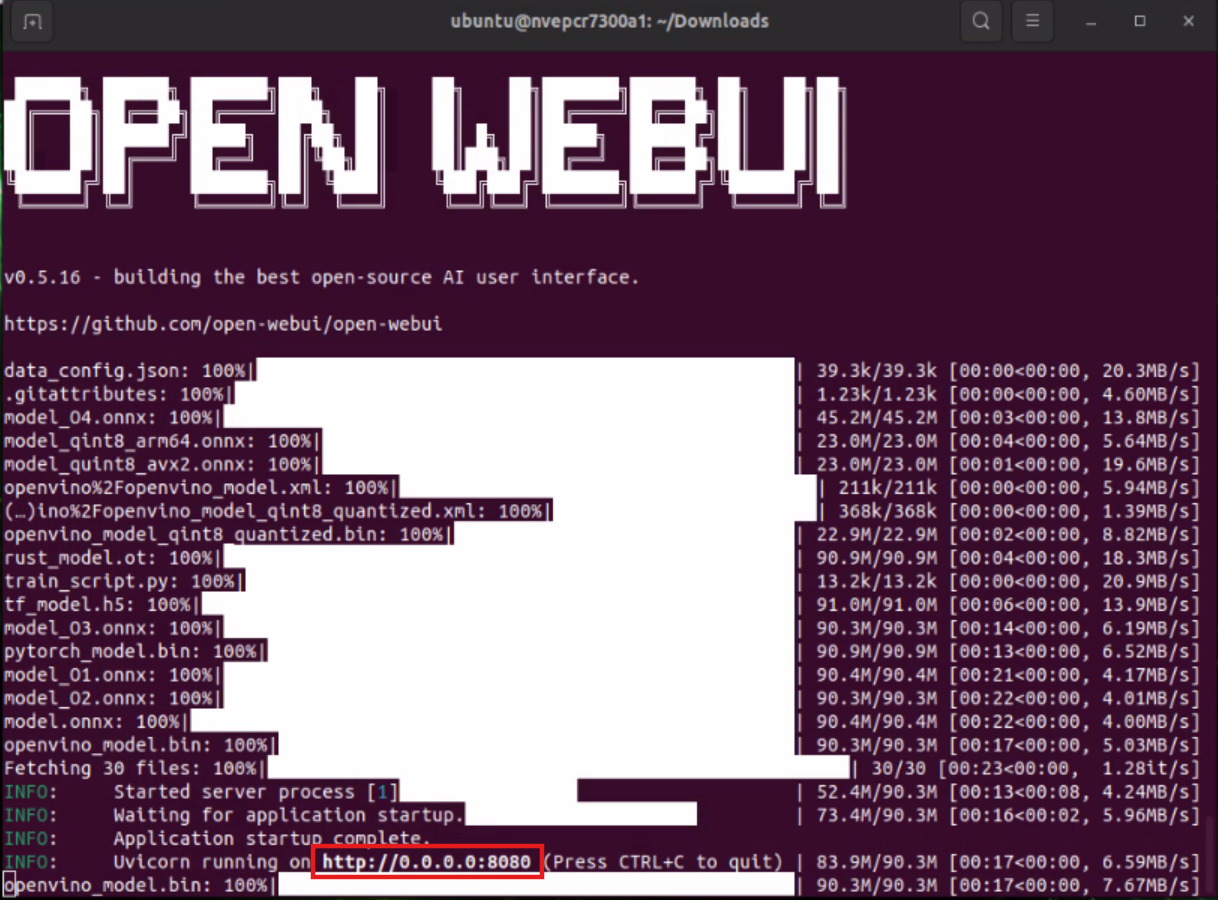
4. 透過瀏覽器操作 AI 大模型 #
步驟 1:進入瀏覽器介面 #
打開 http://0.0.0.0:8080(或命令視窗顯示的 IP),你會看到初始畫面:
點擊 “Get started”。
步驟 2:繼續設定 #
點選 “Okay, Let’s Go!” 開始體驗。

完成後會看到主介面:
步驟 3:下載並選擇大模型 #
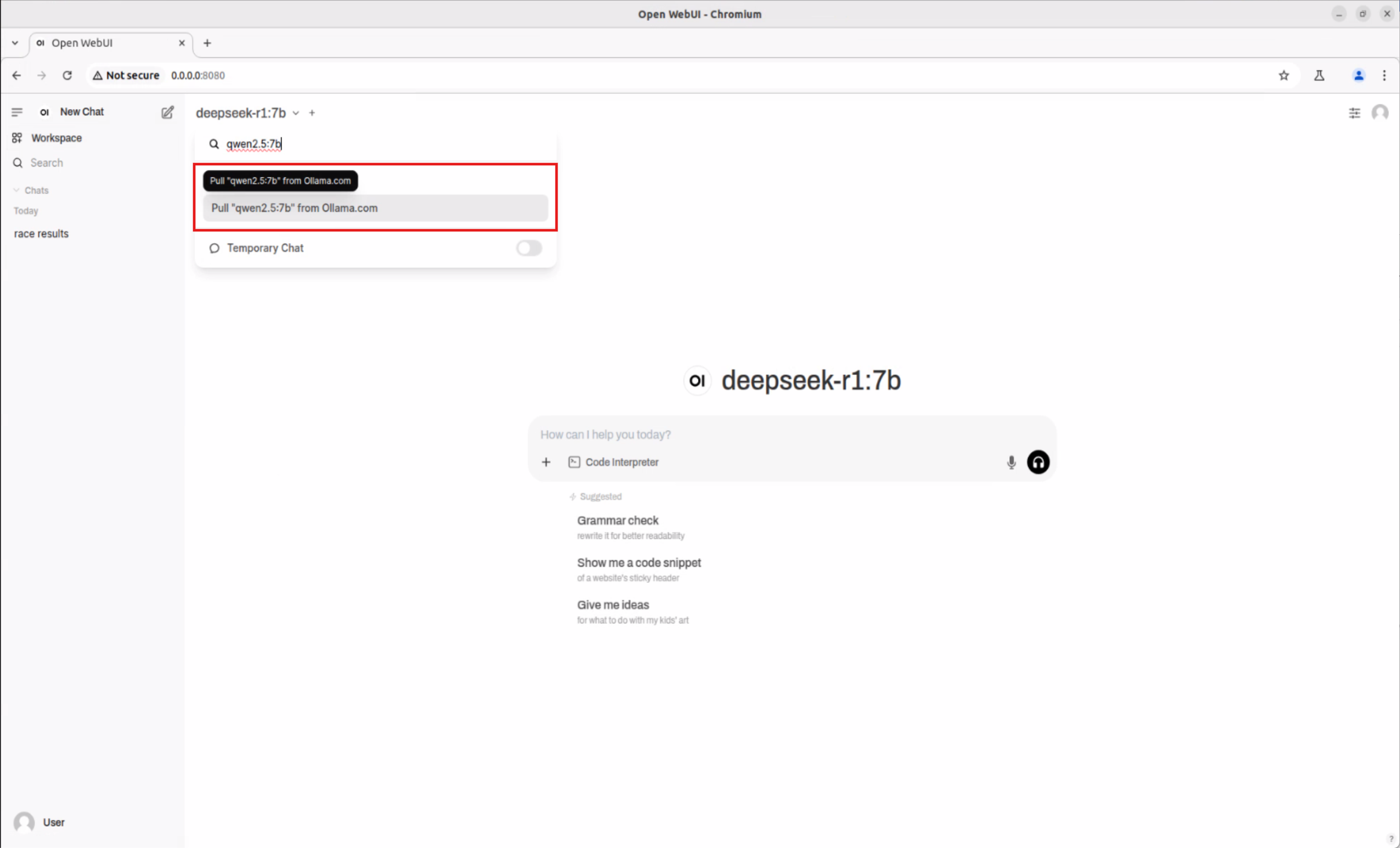
- 在 “Select a model” 旁點選下拉選單,於搜尋框輸入想試的模型名稱(如 deepseek-r1:7b)
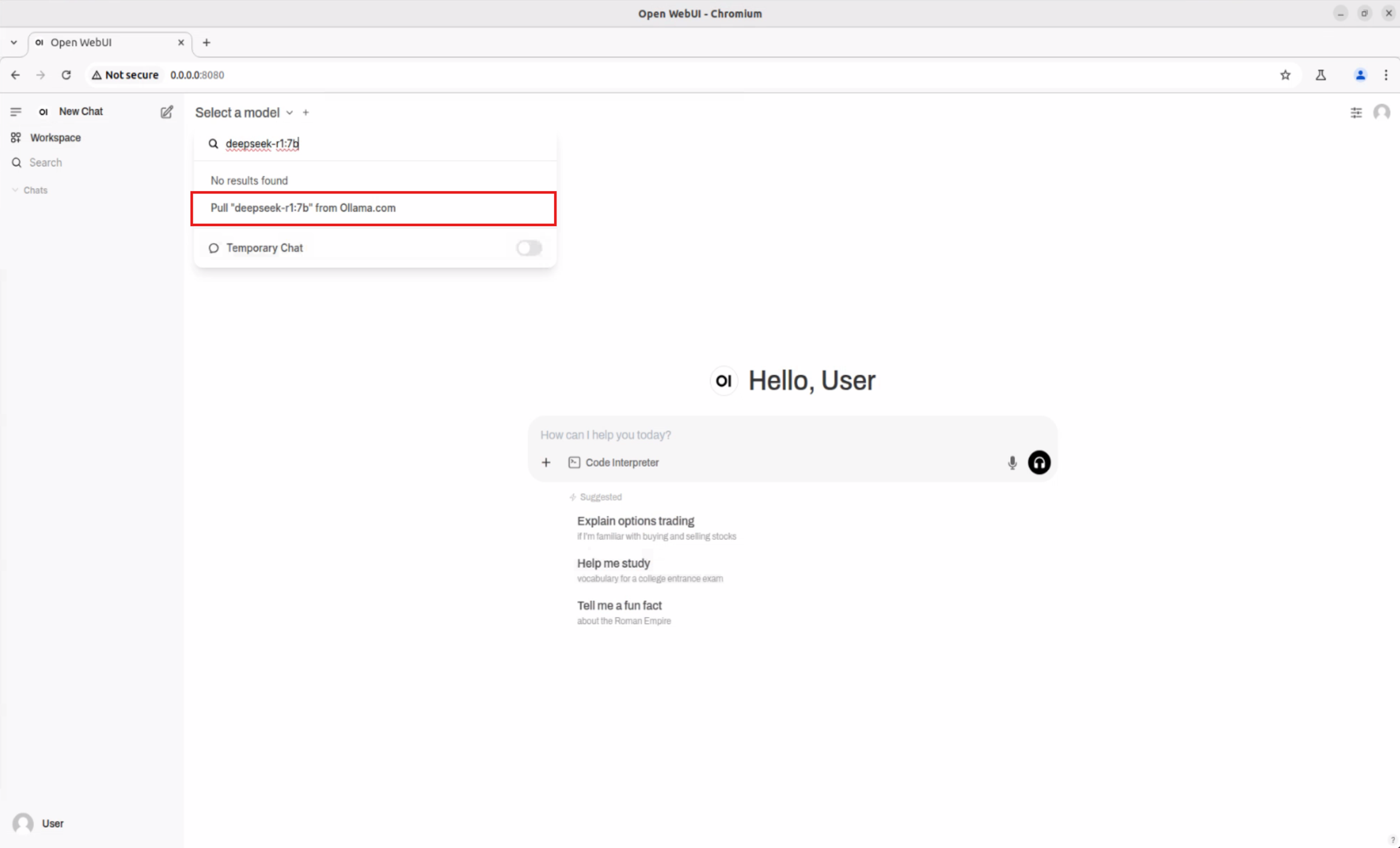
- 依提示直接下載所選模型
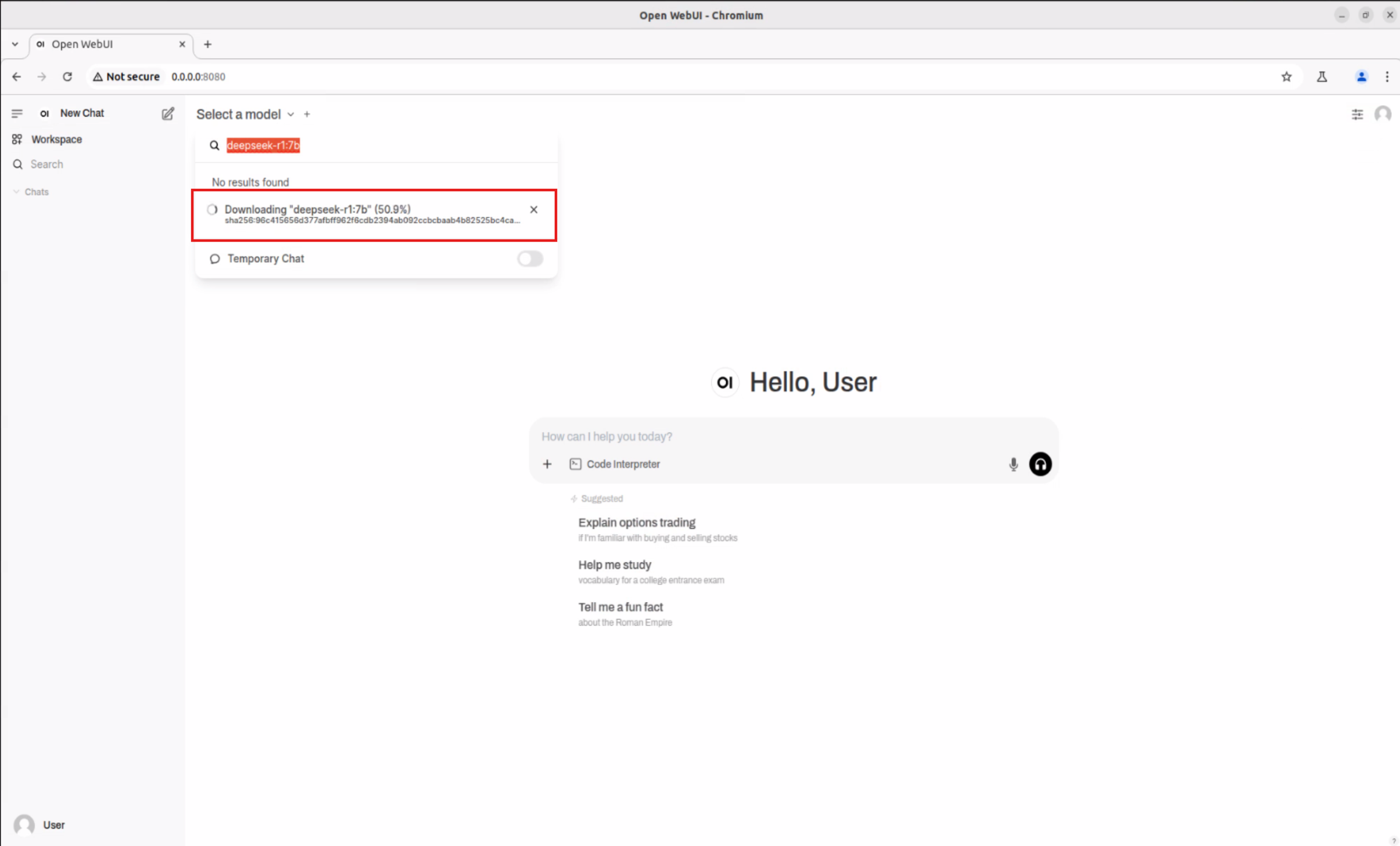
- 下載完成後,從列表選擇新模型(例如 deepseek-r1:7b)
步驟 4:開始與 AI 模型互動! #
選好模型後,你就能像使用 ChatGPT 一樣,自由對話、測試各種應用!
更多模型體驗 #
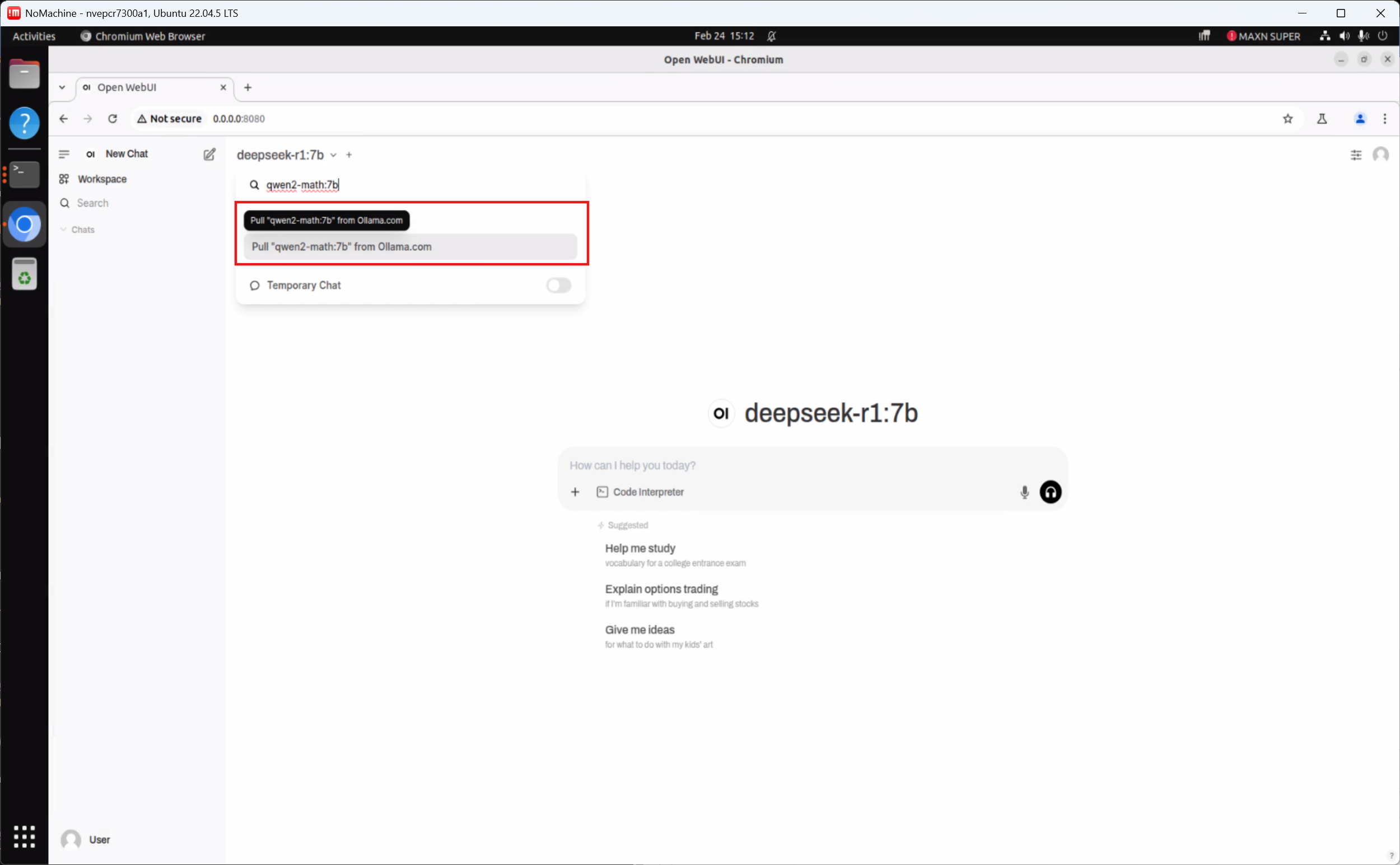
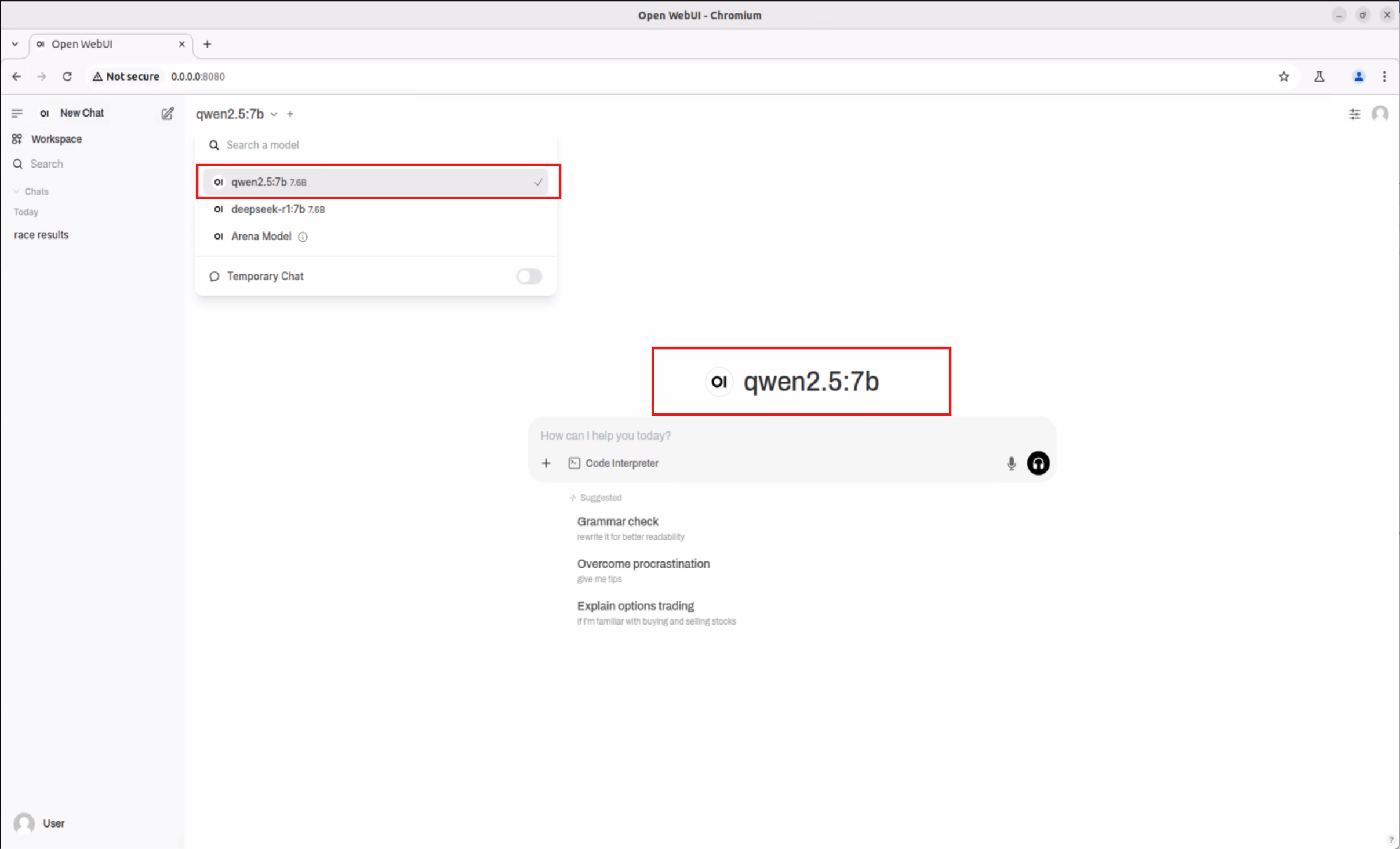
同樣流程,也可下載 Qwen2.5-Math:7b、Qwen2.5:7b 等多種 AI 模型,支援數學推理、專業問答等場景。
-
Qwen2.5-Math:7b
-
Qwen2.5:7b
創新成果與產業應用 #
這次實驗證明,Advantech Jetson Orin 平台不僅能支援多種主流大模型(LLM),還能輕鬆部署在邊緣端,實現:
- 智慧工廠現場即時語音/文字分析
- 零售/客服自動回應
- 智慧醫療資訊查詢
- 交通監控與決策輔助
- 自動化數據推理與知識管理
亮點:
- 不必仰賴雲端,每個現場都能即時 AI 化
- 彈性支援多種模型,快速切換應用
- 開放式架構,方便二次開發與整合
- 高效能、低功耗,適合全天候運作
結論與未來展望 #
本次 Advantech 工程團隊用嚴謹又活潑的實作,證明我們在 AI 邊緣運算領域持續創新、不斷突破。未來,我們將持續優化平台相容性,追蹤新模型與推論架構,協助客戶快速導入最前沿的 AI 技術,抓住每一個數位轉型的機會!
Advantech 將持續以創新為核心,讓 AI 技術真正落地,助力各行各業智慧升級。想了解更多最新實驗與解決方案,歡迎隨時聯繫我們!
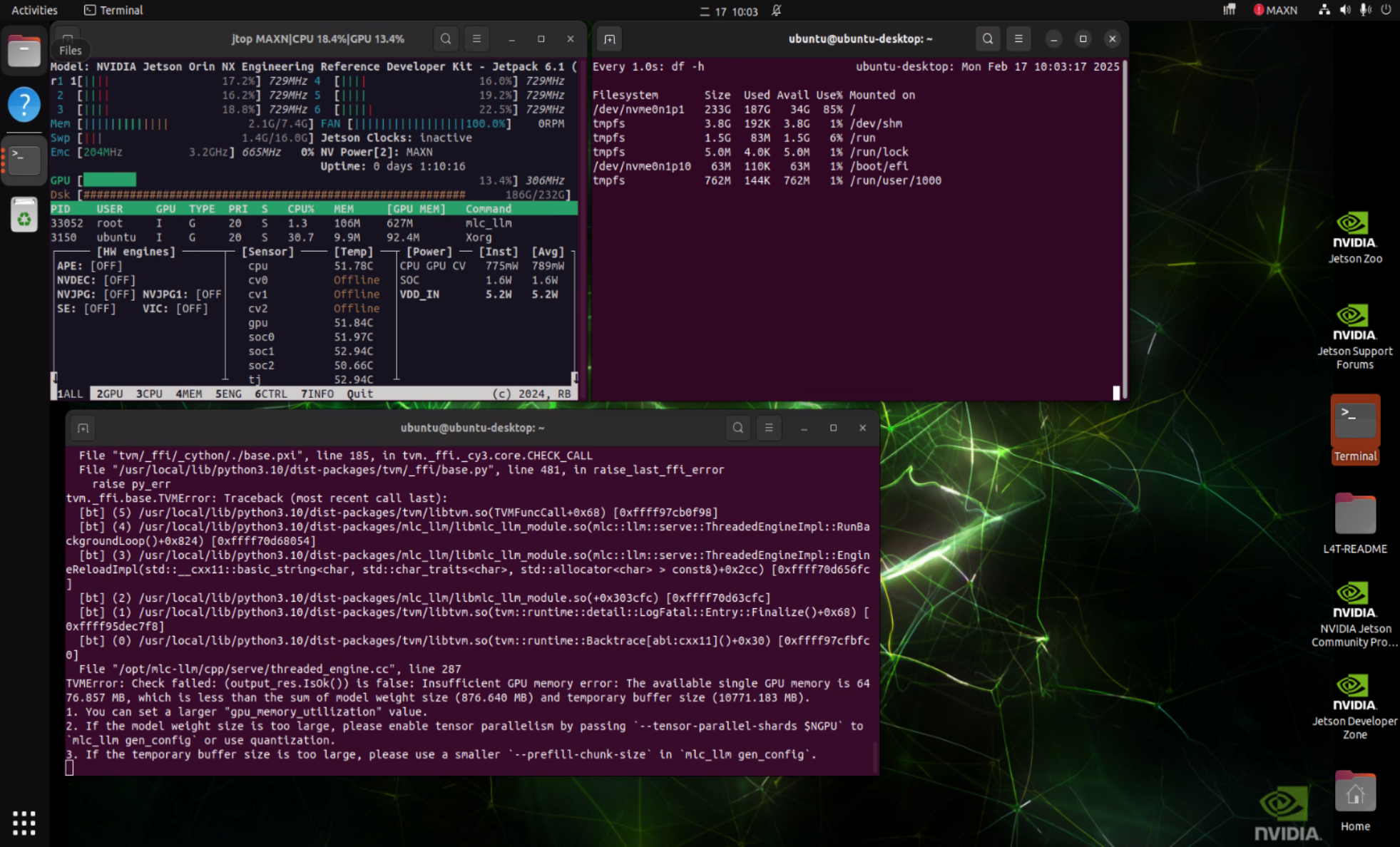
小提醒:目前在 Qwen 架構模型搭配 MLC inference framework 時,可能會遇到相容性問題(如下圖),我們已同步與 NVIDIA 官方積極協調解決中!
參考連結:
—
持續研發、創新不止,Advantech 永遠走在 AI 邊緣運算的最前線!