嘿!各位對邊緣 AI 充滿熱情的夥伴們,想像一下:你手上有個超酷的 AI 應用,準備部署到 Advantech 強大的 Jetson 平台設備上 ( EPC-R7300, AIR-030 ),結果卻發現… 哎呀,軟體版本不相容,這個函式庫要舊版,那個驅動程式要新版,搞得像在玩一場永無止境的「軟體衝突」遊戲!是不是很頭痛?
特別是 NVIDIA JetPack 在升級到 6.x 版本(基於 Ubuntu 22.04)後,雖然帶來了效能提升,但也讓 AI 應用在不同 JetPack 次版本間的「相依性碎片化」問題更加凸顯。簡單來說,你在 JetPack 6.0 上跑得好好的程式,換到 JetPack 6.2 可能就罷工了!這對於需要快速、穩定部署大量 AI 應用的我們來說,絕對是個大挑戰。
別擔心!今天,就讓我們的工程師團隊來分享一個秘密武器,如何透過 Docker 容器技術,徹底解決這個惱人的相依性問題,實現 AI 應用在不同 JetPack 版本間的「版本無痛」部署!
JetPack 6.x 的小煩惱:為什麼會「軟體衝突」? #
雖然 JetPack 6.0 和 6.2 都基於 Ubuntu 22.04,聽起來很像,但還是有些不一樣的地方:
| JetPack 版本 | L4T 版本 | Ubuntu 版本 | 核心驅動/Library 更新 |
|---|---|---|---|
| 6.0 | 36.3.0 | 22.04 | CUDA 12.2 、 TensorRT 8.6 |
| 6.2 | 36.4.3 | 22.04 | CUDA 12.6 、 TensorRT 10.3 |
看到了嗎?即使是同一個主要版本系列,底層的 CUDA、TensorRT 等關鍵 AI 運算函式庫版本還是有差異。這就像是同一個 App,在不同小版本的作業系統上,可能需要不同版本的支援套件才能順利運行。
這會導致什麼問題呢?
- 你在 JetPack 6.0 上辛辛苦苦編譯好的 TensorRT 模型,拿到 6.2 上可能就跑不動了。
- PyTorch 這類深度學習框架,對 CUDA 版本非常敏感,換個 JetPack 版本可能就要重新設定甚至編譯。
- 要在多台不同 JetPack 次版本的設備上部署同一套 AI 程式?簡直是場災難!
容器化:AI 應用的「萬能搬家箱」 #
這時候,Docker 容器技術就登場了!你可以把 Docker 想像成一個輕巧、獨立的「數位搬家箱」。這個箱子裡,不僅裝著你的 AI 應用程式本身,還把程式運行所需的所有「行李」—— 包括特定版本的 CUDA、cuDNN、TensorRT、PyTorch,甚至是作業系統環境——通通打包在一起。
容器化的兩大超能力: #
- 解耦 JetPack 相依性: 你的 AI 應用和它的運行環境被完整封裝在容器裡,就像住進了一個獨立的公寓,不再直接依賴底層 JetPack 的具體版本。只要底層 JetPack 的 GPU 驅動程式與容器內的環境相容,你的應用就能順利運行。
- 「一次打包,到處運行」: 使用 NVIDIA 官方為 Jetson 設計的 L4T Container Base Image(例如基於 L4T 36.2 的映像檔),可以確保容器與 L4T 36.x 系列相容。這意味著,同一個容器映像檔,可以在 JetPack 6.0 和 6.2 環境中都能穩定運行!大大簡化了部署和維護的複雜度。
如何用 Docker 將 AI 封裝容器化 #
以下是我們如何設定環境並成功運行 AI 應用的過程:
首先,要讓 Docker 容器能夠使用 Jetson 強大的 GPU 進行 AI 推論,需要正確設定 Docker 的 runtime。這就像是告訴 Docker:「嘿,別忘了把 GPU 這個加速器也一起打包進去!」
Docker Runtime 設定步驟: #
- 安裝必要的軟體包:
sudo apt update sudo apt install -y nvidia-container curl curl https://get.docker.com | sh && sudo systemctl --now enable docker sudo nvidia-ctk runtime configure --runtime=docker - 重新啟動 Docker 服務並將使用者加入 Docker 群組: 這樣你就不需要每次執行 Docker 指令都輸入
sudo了。sudo systemctl restart docker sudo usermod -aG docker $USER newgrp docker - 編輯 Docker 設定檔: 開啟
/etc/docker/daemon.json,加入以下內容,指定預設使用nvidiaruntime。{ "runtimes": { "nvidia": { "path": "nvidia-container-runtime", "runtimeArgs": [] } }, "default-runtime": "nvidia" } - 再次重新啟動 Docker 服務: 讓新的設定生效。
sudo systemctl restart docker
設定好 Docker 環境後,我們就可以開始下載並運行預先打包好的 AI 應用容器了!NVIDIA 提供了一個方便的工具 jetson-containers,裡面包含了許多常用的 AI 應用容器映像檔。
安裝 Jetson-containers 工具: #
cd $HOME
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
GenAI 範例:運行 Ollama 推論服務 #
我們首先測試了時下最熱門的生成式 AI (GenAI)。使用 Ollama 這個工具,可以在本地端運行大型語言模型 (LLM)。我們直接拉取了 NVIDIA 提供的 Ollama 容器映像檔:
- 下載 Docker Image:
docker pull dustynv/ollama:0.6.8-r36.4 - 啟動容器並運行 Ollama: 使用
jetson-containers run指令可以方便地啟動容器。jetson-containers run dustynv/ollama:0.6.8-r36.4 - 在容器內執行 Ollama 指令: 啟動後,就可以在容器的命令列中運行 Ollama,例如下載並運行一個小型語言模型
gemma3。瞧!模型成功下載並運行,證明 GenAI 應用在容器中順利啟動!ollama run gemma3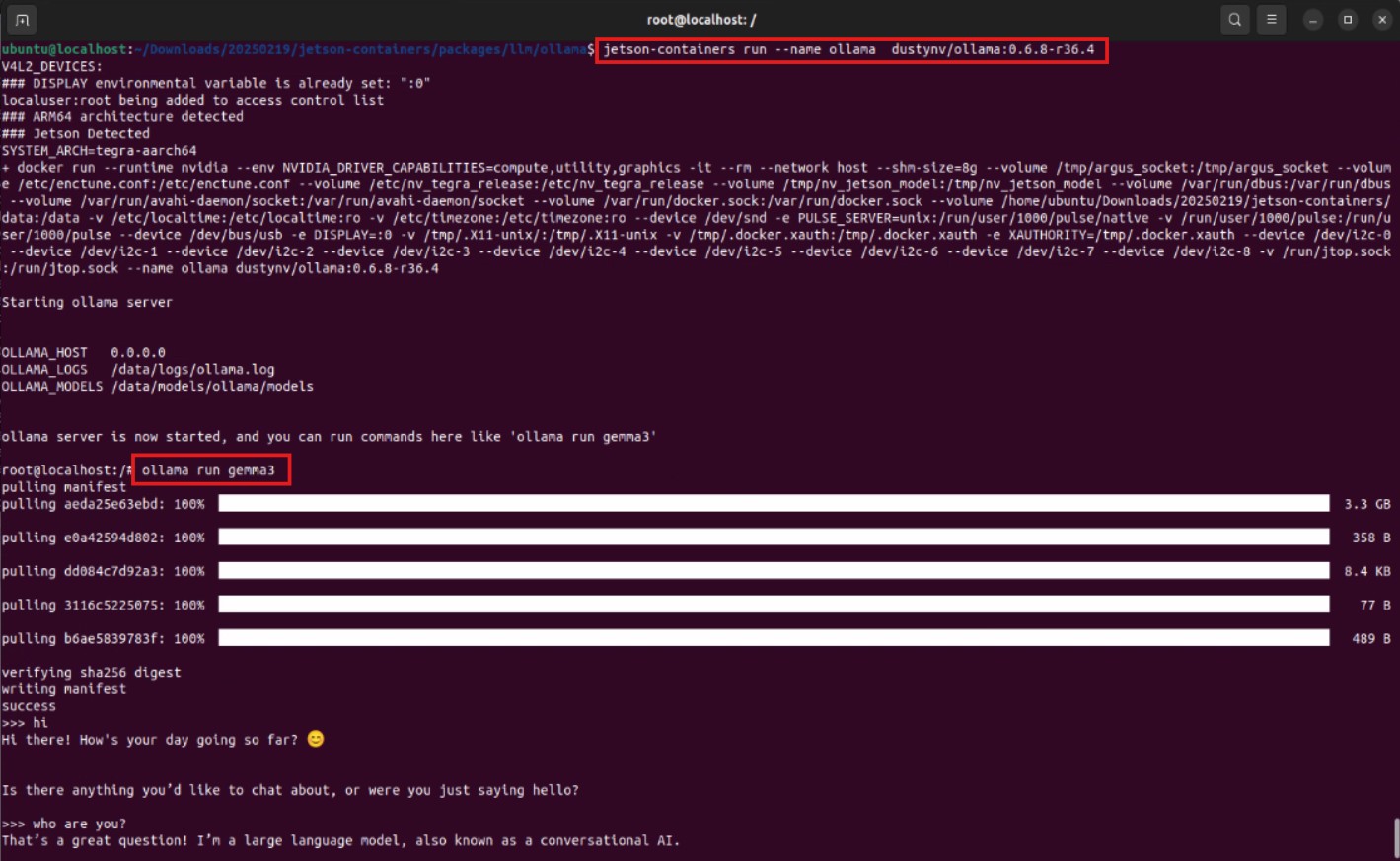
CV 實作範例:運行 Yolo 物體偵測服務 #
接著,我們測試了電腦視覺 (CV) 領域非常經典的 YOLO 物體偵測模型。同樣地,我們拉取了 Ultralytics 官方提供的 YOLO 容器映像檔:
- 下載 Docker Image:
docker pull ultralytics/ultralytics:latest-jetson-jetpack6 - 啟動容器並掛載資料夾: 這次我們需要將本地的資料夾 (
~/yolo-outputs) 掛載到容器內,以便儲存偵測結果。t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker run -it --ipc=host --runtime=nvidia -v ~/yolo-outputs:/ultralytics/runs $t - 在容器內執行 YOLO 推論: 啟動後,在容器的命令列中執行 YOLO 推論指令,指定模型 (
yolo11n.pt) 和輸入來源(這裡使用一張 Ultralytics 提供的公車圖片)。結果出爐!YOLO 模型成功在容器內對圖片進行了物體偵測,並將結果儲存到我們指定的資料夾中。這再次證明了容器化部署的可行性!yolo predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg'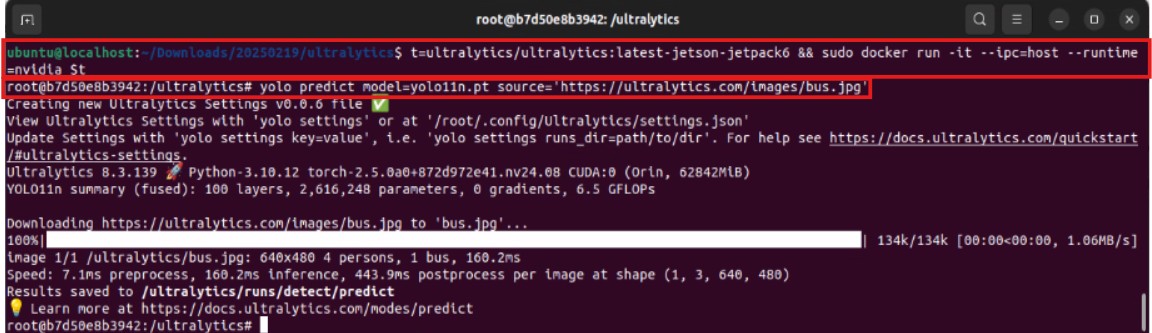
容器化部署的價值:不只解決問題,更創造優勢! #
我們成功驗證了在 JetPack 6.x 平台上,利用 Docker 容器技術可以有效地解決 AI 應用因 JetPack 次版本差異導致的相依性問題。
這對 Advantech 的客戶和合作夥伴意味著什麼?
- 部署更快速、更穩定: 不再需要為每個 JetPack 版本單獨配置和測試環境,打包好的容器可以在相容的 JetPack 設備上即時運行,大大縮短部署時間,減少錯誤。
- 維護更簡單: 應用程式和其環境被隔離,更新或回溯版本只需要替換容器映像檔,不影響底層系統。
- 跨平台移植更容易: 同一個容器映像檔,可以在不同型號、不同 JetPack 次版本的 Advantech Jetson 設備上運行,擴展應用範圍。
- 加速創新: 工程師可以更專注於 AI 應用本身的開發和優化,而不是被底層環境配置所困擾,加速新技術和新應用的落地。
結語:持續創新,為邊緣 AI 注入強勁動能! #
無論是生成式 AI 還是電腦視覺,容器化部署都提供了一個標準化、高效率的途徑。未來,我們將繼續深入研究,探索更多容器技術在邊緣 AI 領域的潛力,例如邊緣容器管理、模型遠端更新等,持續為我們的客戶和合作夥伴提供最領先、最可靠的邊緣 AI 解決方案。