嘿!各位AI愛好者、我們的夥伴AE與銷售精英們,以及所有對前瞻技術充滿好奇的朋友們!
想像一下,你正在與一個AI助理流暢地對話,它幾乎能即時理解你的需求並給出回應,沒有惱人的延遲。這不是遙不可及的未來,而是我們Advantech正在努力實現的目標!在AI浪潮中,大型語言模型(LLM)無疑是耀眼的明星,它們能寫作、翻譯、程式設計,甚至進行複雜的推理。但要讓這些龐大的模型在邊緣或雲端設備上「開口說話」得又快又好,可不是件容易的事。這背後需要強大的硬體支援和高效的軟體技術。
今天,我們要跟大家分享Advantech工程團隊的一項令人振奮的實驗成果。我們深入探索了如何結合高效能的 Qualcomm Cloud AI 100 Ultra 顯卡 與專為LLM推理設計的開源函式庫 vLLM,來大幅提升AI模型的執行效率。這不僅展現了Advantech在AI領域持續投入研發的決心,也為我們的客戶和合作夥伴開啟了更多可能性!
為什麼 LLM 推理又快又好這麼重要?
大型語言模型雖然功能強大,但它們的「體積」也非常龐大,動輒數十億甚至上千億個參數。在實際應用中(也就是「推理」階段),每次使用者輸入一個問題或指令,模型都需要進行大量的計算才能生成回應。如果這個過程太慢,使用者體驗就會大打折扣,許多即時性的應用(如智慧客服、語音助理、即時翻譯)也將難以實現。
傳統的推理方法往往效率不高,資源佔用大。這時候,像 vLLM 這樣的技術就應運而生了。vLLM 是一個專門為大型語言模型推理設計的函式庫,它採用了許多先進的技術(例如 PagedAttention),可以顯著提高吞吐量(throughput,想像成AI每秒能處理或生成多少個詞/符號)並降低延遲,讓AI的回應速度更快、更流暢。
而 Qualcomm Cloud AI 100 Ultra 顯卡,正是為高效能AI推理而生的硬體加速器,它提供了強大的計算能力,非常適合用來運行這些複雜的AI模型。
將 vLLM 的軟體優勢與 Qualcomm 硬體的強大性能結合,正是我們這次實驗的核心目標!
實驗大解密:我們是怎麼做的?
為了驗證 vLLM 在 Qualcomm GPU 上的實際表現,我們的工程師進行了一系列的環境搭建與效能測試。整個過程可以概括為以下幾個關鍵步驟:
-
準備硬體與系統環境: 首先,我們需要一台搭載了 Qualcomm Cloud AI 100 Ultra 顯卡的設備,並安裝好 Ubuntu 22.04 作業系統。這是進行實驗的基礎平台。
-
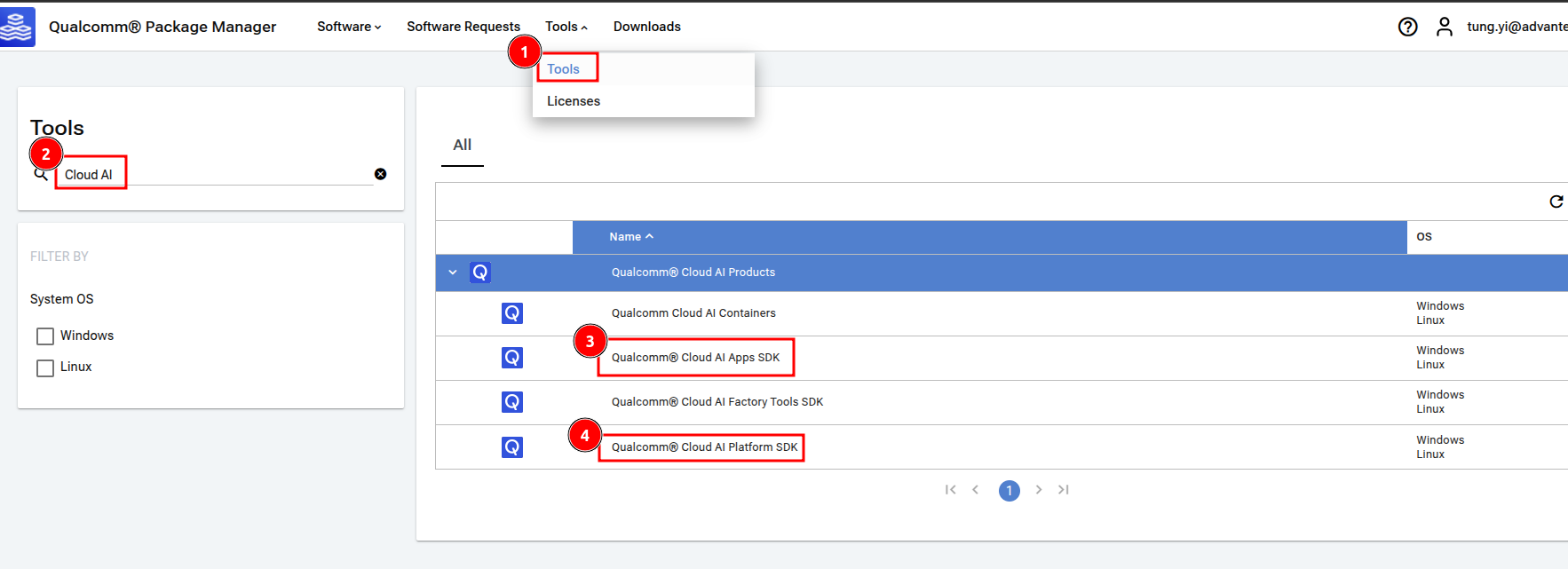
安裝 Qualcomm 提供的 SDK: Qualcomm 為其AI顯卡提供了專用的軟體開發工具包 (SDK),包括 Apps SDK 和 Platform SDK。這些 SDK 包含了驅動程式、函式庫以及開發工具,是讓軟體能夠充分利用硬體效能的關鍵。我們從 Qualcomm Package Manager 下載了所需的 SDK 版本。
unzip aic_apps.Core.1.19.6.0.Linux-AnyCPU.zip unzip aic_platform.Core.1.19.6.0.Linux-AnyCPU.zip ./qaic-apps-1.19.6.0/x86_64/deb/install.sh ./qaic-platform-sdk-1.19.6.0/x86_64/deb/install.sh安裝完成後,重啟系統讓設定生效。我們可以透過
qaic-util -t 1指令來檢查 GPU 是否正常工作並查看其狀態,如果看到類似下圖的輸出,就表示硬體和基礎軟體環境都準備好了!qaic-util -t 1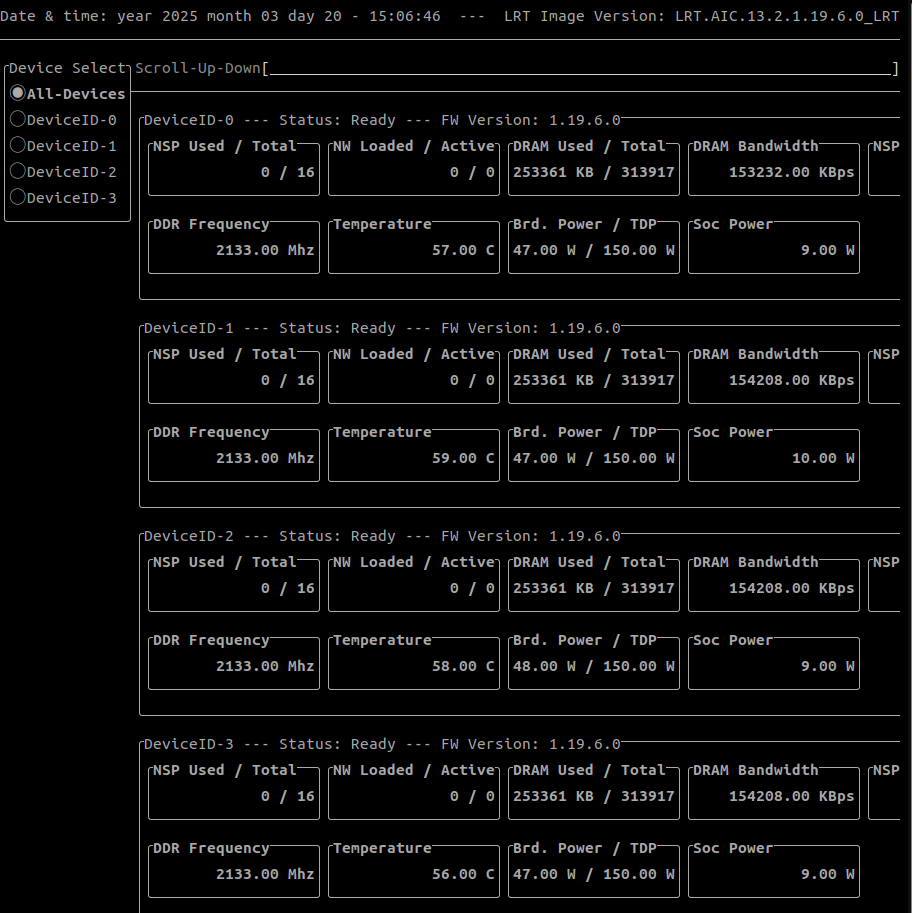
-
建立 vLLM 的 Docker 環境: 為了方便部署和管理,我們將 vLLM 及其相關依賴打包到一個 Docker 容器中。這一步驟使用了 Qualcomm SDK 提供的工具來建立包含 vLLM 的 Docker Image。
cd qaic-apps-1.19.6.0/common/tools/docker-build/ python3.10 -m venv venv source venv/bin/activate pip install -r requirements.txt python build_image.py --user_specification_file ./sample_user_specs/user_image_spec_vllm.json --apps_sdk <path_to_apps_sdk_zip_file> --platform_sdk <path_to_platform_sdk_zip_file> --tag 1.19.6.0建立成功後,使用
docker images指令可以看到生成的 vLLM Docker Image。docker images
-
配置多 GPU 使用 (Disable ACS): 如果需要同時利用多個 Qualcomm GPU 來加速推理(這對於運行更大的模型或處理更多並發請求非常重要),我們需要進行額外的配置來禁用 ACS (Access Control Services)。這確保了多個設備可以被有效地協同使用。
python QAicChangeAcs.py all
-
啟動 vLLM OpenAI Compatible Server: 進入建立好的 Docker 容器,並啟動 vLLM 提供的 OpenAI Compatible API Server。這個 Server 讓我們可以透過標準的 API 介面來呼叫模型進行推理,就像使用 OpenAI 的服務一樣方便。我們指定了要載入的模型(例如 TinyLlama 或 DeepSeek-8B)、使用的設備(一個或多個 Qualcomm GPU),以及一些優化參數。 首先,運行 Docker 容器並進入其 bash 環境:
docker run -it --rm --entrypoint bash --name tytest -p 8000:8000 --device=/dev/accel/accel0 [--device=/dev/accel/accel1] [--device=/dev/accel/accel2] [--device=/dev/accel/accel3] -e VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 [-e MODEL=deepseek-ai/DeepSeek-R1-Distill-Llama-8B] [-e HF_TOKEN=hf_xxxxxxxx] -v /home/adv/.cache/:/root/.cache ty-qaiqaic-x86_64-ubuntu20-py310-py38-release-qaic_platform-qaic_apps-pybase-pytools-vllm:1.19.6.0然後在容器內啟動 vLLM Server:
source /opt/vllm-env/bin/activate python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 8000 --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 --max-model-len 4096 --max-num-seq 16 --max-seq_len-to-capture 128 --device qaic --block-size 32 --quantization mxfp6 --kv-cache-dtype mxint8 --device-group 0,1,2,3 -
進行效能基準測試 (Benchmarking): Server 啟動並成功載入模型後,我們就可以進行壓力測試了!我們使用了業界常用的 ShareGPT 資料集來模擬真實的使用情境,測試在不同模型和不同數量 GPU 下的推理效能,特別是關注「吞吐量 (Total Token throughput)」。 首先下載測試資料集:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json然後在 Docker 容器內執行基準測試腳本:
docker exec -it tytest bash cd /opt/qti-aic/integrations/vllm/ python3 benchmarks/benchmark_serving.py --backend openai --base-url http://127.0.0.1:8000 --dataset-name=sharegpt --dataset-path=./ShareGPT_V3_unfiltered_cleaned_split.json --sharegpt-max-input-len 128 --sharegpt-max-model-len 256 --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 --seed 12345
令人振奮的成果:效能顯著提升!
經過嚴謹的測試,我們比較了使用不同版本的 Qualcomm SDK (1.18.2.0 vs 1.19.6.0) 在 Qualcomm Cloud AI 100 Ultra 顯卡上運行 TinyLlama (1.1B) 和 DeepSeek-8B 這兩個模型時的效能表現。
以下是我們整理的吞吐量 (Total Token throughput, tok/s) 比較結果:
模型:TinyLlama/TinyLlama-1.1B-Chat-v1.0 使用設備:1 個 Qualcomm GPU
| SDK 版本 | 總吞吐量 (tok/s) |
|---|---|
| 1.18.2.0 | 321.19 |
| 1.19.6.0 | 614.35 |
哇!看到這個數字是不是很驚訝?對於 TinyLlama 模型,僅僅是更新到新版的 SDK,吞吐量就實現了 接近翻倍 的提升!這意味著在相同的時間內,AI 模型可以處理更多的請求或生成更多的內容,效率大大提高。
以下是測試結果截圖:
| SDK 版本 | 測試結果截圖 |
|---|---|
| SDK 1.18.2.0 (1 device) |
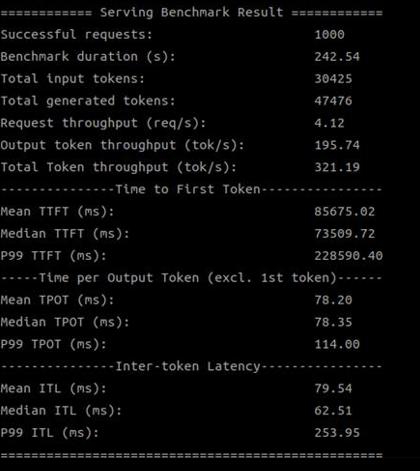
|
| SDK 1.19.6.0 (1 device) |
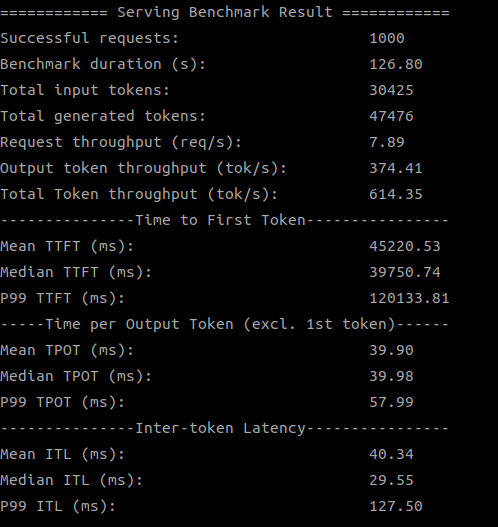
|
模型:deepseek-ai/DeepSeek-R1-Distill-Llama-8B 使用設備:1 個 Qualcomm GPU
| SDK 版本 | 總吞吐量 (tok/s) |
|---|---|
| 1.18.2.0 | 158.10 |
| 1.19.6.0 | 162.48 |
對於 DeepSeek-8B 這個更大的模型,新版 SDK 在單一 GPU 上的提升雖然不如 TinyLlama 那麼巨大,但也顯示出穩定的進步。
以下是測試結果截圖:
| SDK 版本 | 測試結果截圖 |
|---|---|
| SDK 1.18.2.0 (1 device) |
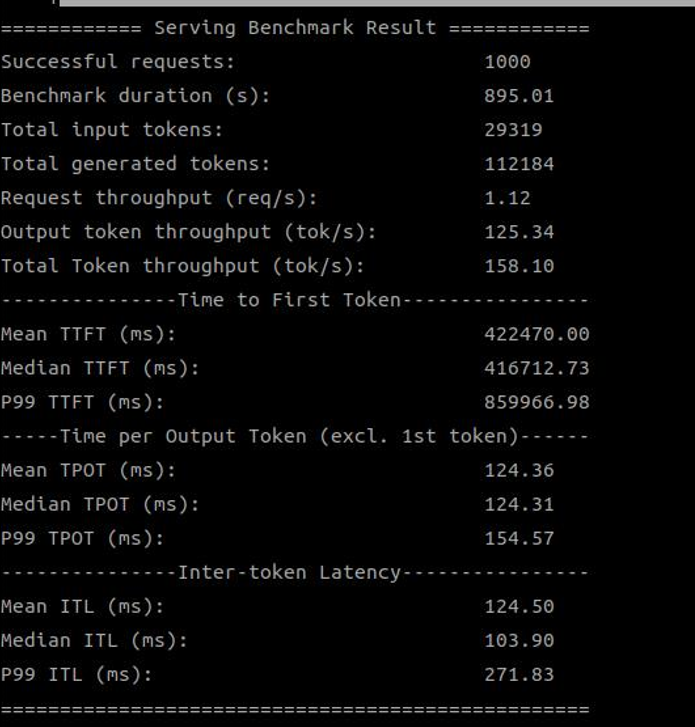
|
| SDK 1.19.6.0 (1 device) |
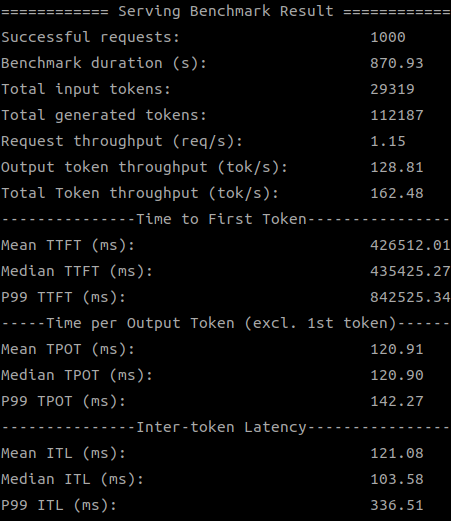
|
模型:deepseek-ai/DeepSeek-R1-Distill-Llama-8B 使用設備:2 個 Qualcomm GPU
| SDK 版本 | 總吞吐量 (tok/s) |
|---|---|
| 1.18.2.0 | 228.15 |
| 1.19.6.0 | 254.62 |
模型:deepseek-ai/DeepSeek-R1-Distill-Llama-8B 使用設備:4 個 Qualcomm GPU
| SDK 版本 | 總吞吐量 (tok/s) |
|---|---|
| 1.18.2.0 | 225.16 |
| 1.19.6.0 | 339.29 |
當我們使用多個 Qualcomm GPU 來運行 DeepSeek-8B 模型時,新版 SDK 的優勢就更加明顯了,特別是在使用 4 個 GPU 時,吞吐量提升了超過 50%!這證明了新版 SDK 在多設備協同工作方面的優化,能更好地釋放硬體潛力。
以下是測試結果截圖:
| SDK 版本 | 測試結果截圖 |
|---|---|
| SDK 1.18.2.0 (2 devices) |
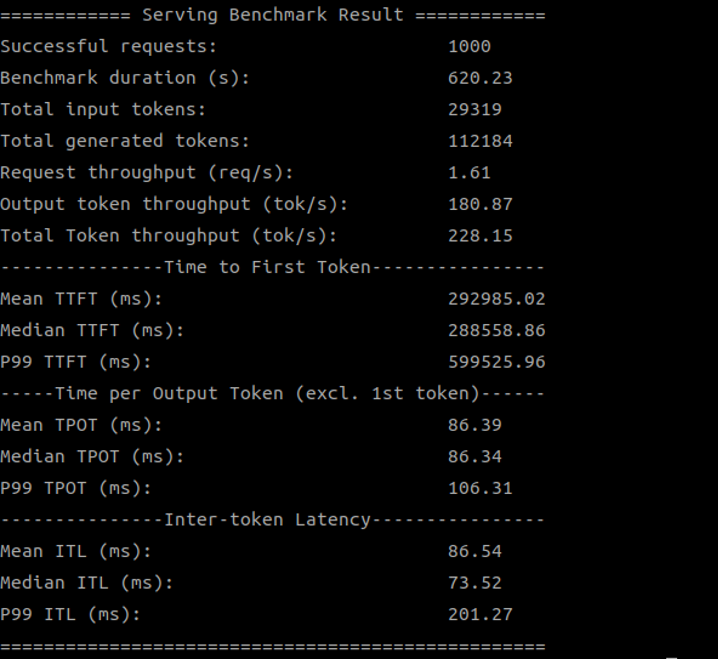
|
| SDK 1.19.6.0 (2 devices) |
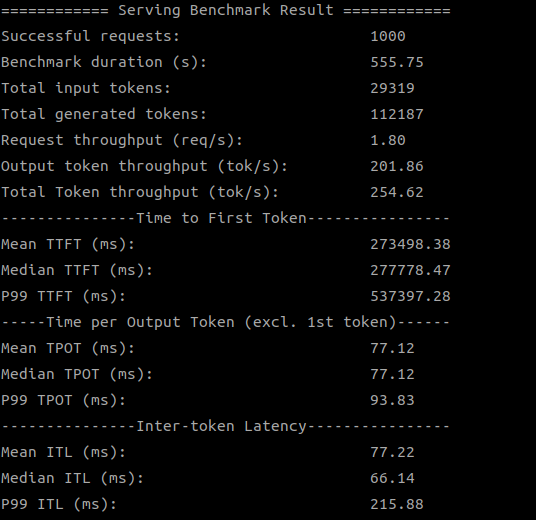
|
| SDK 1.18.2.0 (4 devices) |
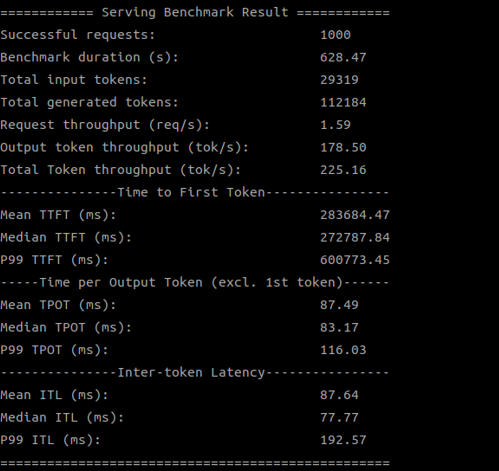
|
| SDK 1.19.6.0 (4 devices) |
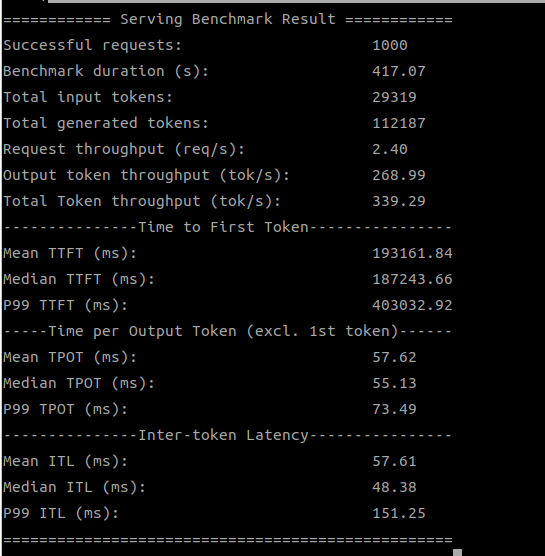
|
這些成果意味著什麼?
這次實驗的成功,不僅驗證了 vLLM 在 Qualcomm Cloud AI 100 Ultra 顯卡上的可行性,更重要的是,它清晰地展示了透過軟體與硬體的緊密結合與持續優化,我們可以顯著提升大型語言模型的推理效能。
對於 Advantech 而言,這代表著:
- 更強大的 AI 解決方案: 我們能夠為客戶提供運行 LLM 更快、更有效率的硬體平台。
- 更廣泛的應用場景: 高效能的 LLM 推理能力,將助力智慧製造、智慧醫療、智慧零售等領域實現更先進的 AI 應用,例如即時語音互動、智慧決策輔助、自動內容生成等。
- 持續的技術領先: 這次實驗證明了 Advantech 工程團隊具備深入研究和整合最新 AI 技術的能力,我們不斷探索如何為客戶提供最佳的 AI 推理解決方案。
結論與未來展望
透過這次在 Qualcomm Cloud AI 100 Ultra 顯卡上使用 vLLM 進行 LLM 推理的實驗,我們成功展示了顯著的效能提升,特別是藉由更新 SDK 版本和利用多個 GPU。這再次印證了軟體優化對於釋放硬體潛力的重要性。
Advantech 將繼續在這個領域深耕,探索更多優化技術,並將這些高效能的 AI 推理能力整合到我們的產品和解決方案中。我們相信,透過不斷的研發與創新,Advantech 將能為客戶帶來更智慧、更高效的未來!
如果您對我們的 AI 解決方案感興趣,或是想了解更多技術細節,歡迎隨時與我們的 AE 或銷售團隊聯繫!我們期待與您一同開啟 AI 的無限可能!
參考資料: