你是否曾想像過,讓AI像一位經驗豐富的專家,不僅能理解你的提問,更能從龐大的資料庫中,精準找出答案並清晰地呈現在你面前?今天,就讓我們一起踏上這趟AI探險之旅,看看研華的工程師們如何在我們的邊緣AI運算平台 AIR-310 上,從零開始,一步步打造並驗證一個強大的檢索增強生成(RAG)系統!
這不只是一次技術實驗,更是研華在AI領域持續探索、勇於創新的最佳證明。準備好了嗎?讓我們一起揭開RAG系統的神秘面紗!
為什麼我們需要RAG?AI問答的秘密武器! #
在AI的世界裡,大型語言模型(LLM)就像一位博學的通才,能言善道,知識淵博。但如果我們想讓它針對特定領域(比如公司的產品規格、技術文件)提供精準答案,就好像要求一位歷史學家突然變成物理學專家一樣,有點強人所難。
這時候,檢索增強生成 (Retrieval Augmented Generation, RAG) 技術就派上用場了!
想像一下:
- 大型語言模型 (LLM):一位非常聰明、學習能力超強的助理。
- 你的專屬資料庫 (Knowledge Base):一本或多本記載著公司內部知識、產品規格、客戶案例的「秘笈」。
- RAG系統:一位超級圖書管理員,當助理接到你的問題時,這位管理員會先去「秘笈」中快速找到最相關的幾頁,然後交給聰明助理。助理再結合這些精華內容和它原有的知識,給你一個既專業又貼合你需求的完美答案!
簡單來說,RAG讓LLM不再只是「泛泛而談」,而是能針對你的特定資料「深入挖掘」,提供更準確、更即時、更客製化的回答。這對於企業知識管理、智能客服、產品推薦等應用場景,無疑是一大利器!市場對於能夠快速導入、高效運作的AI解決方案需求日益迫切,而研華正走在這波浪潮的前端。
AIR-310實戰秀:打造RAG系統的幕後直擊 #
我們的工程師選擇了研華高效能的邊緣運算平台 AIR-310 作為這次實戰的舞台。這款硬體憑藉其強大的 Intel CPU 和 NVIDIA GPU,為複雜的AI運算提供了堅實的基礎。現在,就讓我們跟隨工程師的腳步,看看這個RAG系統是如何一步步誕生的吧!
(溫馨提醒:以下步驟保留了原始技術細節,技術愛好者可以深入研究,而非技術背景的讀者可以快速瀏覽,感受一下研華工程師的巧手匠心!)
前置條件:打好AI的「地基」 #
就像蓋房子需要穩固的地基一樣,建構RAG系統也需要合適的軟硬體環境。
硬體需求 (AIR-310) #
- Intel x86 架構 CPU (64 位元)
- 支援 CUDA 的 NVIDIA GPU (例如:NVIDIA RTX 系列等)
- 至少 16GB VRAM
- 至少 50GB 可用磁碟空間 (用於 Docker 映像檔、模型及資料)
軟體需求 #
- 作業系統:Ubuntu 22.04 LTS (或相容的 Linux 發行版)
- NVIDIA GPU 驅動程式 (建議版本 525 或更新)
- CUDA Toolkit (版本 11.8 或更新)
- Docker (版本 20.10 或更新)
- 用於 Docker 中 GPU 加速的 NVIDIA Container Toolkit
網路需求 #
- 穩定網路連線,用於下載 Docker 映像檔和模型
步驟 1:環境設定 – 讓AI引擎順暢運轉 #
這一步的目標是確保我們的 AIR-310 擁有執行AI任務所需的核心驅動力。
1.1 安裝 CUDA Toolkit #
CUDA 是 NVIDIA 開發的平行運算平台與編程模型,能讓GPU分擔密集的運算任務,大幅提升AI模型的訓練與推論速度。
-
下載並安裝最新版 CUDA 參考 NVIDIA CUDA 下載頁面,根據環境配置選擇適合的安裝包後,安裝 CUDA:
wget https://developer.download.nvidia.com/compute/cuda/12.9.0/local_installers/cuda_12.9.0_575.51.03_linux.run sudo sh cuda_12.9.0_575.51.03_linux.run注意:NVIDIA CUDA 安裝時在圖形頁面中,建議選擇 install 選項進行安裝 (包括 NVIDIA 驅動程式、CUDA Toolkit 12.9 等)
-
安裝完成後,檢查 NVIDIA:
nvidia-smi(這個指令能顯示GPU的狀態,確認驅動和CUDA是否正常工作。)
-
設定環境變數:
echo 'export PATH=/usr/local/cuda-12.9/bin:$PATH' >> ~/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.9/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc source ~/.bashrc(告訴系統去哪裡找到CUDA的相關工具。)
-
驗證安裝:
nvcc --version(確認CUDA編譯器已成功安裝。)
1.2 安裝 Docker 和 NVIDIA Container Toolkit #
Docker 就像一個個輕巧的「貨櫃」,可以將應用程式和其所有依賴的環境打包在一起,方便部署和管理。NVIDIA Container Toolkit 則讓這些「貨櫃」也能使用GPU的強大運算力。
-
安裝 Docker:
sudo apt update sudo apt install -y docker.io sudo systemctl start docker sudo systemctl enable docker sudo usermod -aG docker $USER -
安裝 NVIDIA Container Toolkit:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt install -y nvidia-container-toolkit sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker注意:安裝過程中若出現錯誤 (
command 'curl' not found),請先執行snap install curl命令後再次執行上述命令 -
驗證 NVIDIA Docker 配置:
docker run --rm --gpus all nvidia/cuda:12.9.0-base-ubuntu22.04 nvidia-smi(這個指令會嘗試在Docker容器內執行
nvidia-smi,成功即代表GPU資源可以被Docker容器使用了。)注意:若提示無法找到映像檔或達到未認證的拉取速率限制,則需要先登入 Docker Hub 後再進行操作
步驟 2:建立配置 Docker 網路 – 讓AI元件順暢溝通 #
我們將為後續安裝的 Ollama(LLM服務)和 OpenWebUI(使用者介面)建立一個專屬的內部網路,確保它們之間溝通無礙。
docker network create llm-network
docker network ls
步驟 3:安裝並配置 Ollama – 召喚你的AI大腦 #
Ollama 是一個能讓你輕鬆在本機執行大型語言模型的工具。我們將透過它來部署我們選用的AI模型。
3.1 以 Docker 方式安裝 Ollama #
-
建立主機上的模型儲存目錄:
mkdir -p ~/ollama/models(AI模型檔案會存放在這裡。)
-
執行 Ollama 容器並連接到自訂網路:
docker run -d --gpus all \ -v ~/ollama/models:/root/.ollama \ -p 11434:11434 \ --name ollama \ --network llm-network \ --restart always \ ollama/ollama說明:
-d:在背景執行容器--gpus all:啟用 GPU 加速,讓模型跑得更快!-v:將我們剛建立的模型儲存目錄掛載到容器內。-p:將容器的11434連接埠映射到主機,方便我們存取Ollama服務。--name ollama:給這個容器取個名字。--network llm-network:把它加入先前建立的專用網路。
-
檢查容器是否正常運行:
docker ps -
驗證 Ollama 是否運行中:
curl http://localhost:11434如果看到 “Ollama is running”,就表示AI大腦的核心服務已經啟動成功!
3.2 下載模型 – 為AI大腦裝填知識 #
我們選擇了 gemma3:4b 作為主要的聊天模型(Chat Model),以及 bge-m3 作為嵌入模型(Embedding Model)。嵌入模型的功能是將文字轉換成電腦能理解的數字向量,是RAG系統中實現「語義搜尋」的關鍵。
docker exec -it ollama ollama pull gemma3:4b
docker exec -it ollama ollama pull bge-m3
docker exec -it ollama ollama list # 驗證模型是否下載成功,應列出 gemma3:4b 和 bge-m3
步驟 4:安裝並配置 OpenWebUI – 給AI一個友善的互動介面 #
OpenWebUI 是一個開源的網頁使用者介面,可以讓我們方便地與 Ollama 上的語言模型互動,並且支援RAG功能。
4.1 以 Docker 方式安裝 OpenWebUI #
-
建立主機上的 OpenWebUI 資料目錄:
mkdir -p ~/openwebui/data -
執行 OpenWebUI 容器並連接到自訂網路:
docker run -d \ -p 8080:8080 \ -v ~/openwebui/data:/app/backend/data \ --name openwebui \ --network llm-network \ --restart always \ ghcr.io/open-webui/open-webui:main(同樣地,我們將OpenWebUI也用Docker容器的方式執行,並連接到
llm-network。) -
驗證 OpenWebUI:
- 開啟瀏覽器,存取
http://localhost:8080。如果看到登入介面,就代表成功啦!
- 開啟瀏覽器,存取
4.2 初始化 OpenWebUI – 設定AI的「感官」 #
-
開啟
http://localhost:8080,註冊新帳號,並成功登入。 -
連接到 Ollama 服務:
- 設定 Ollama API 地址。這一步是告訴 OpenWebUI,我們的AI大腦(Ollama)在哪裡。
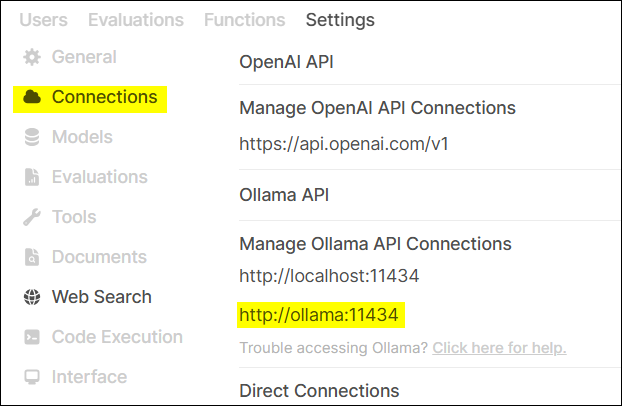
- 設定 Embedding Model。指定我們之前下載的
bge-m3模型,用於處理知識庫文件。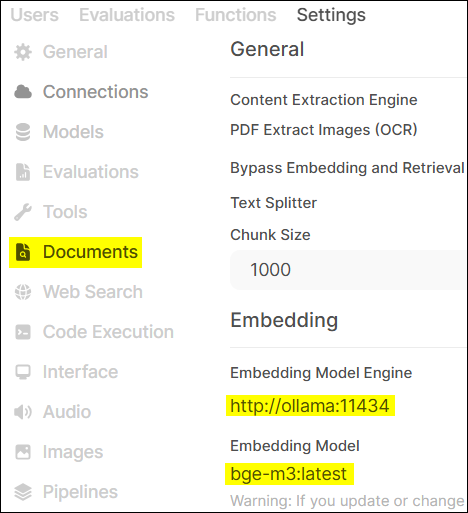
- 設定 Ollama API 地址。這一步是告訴 OpenWebUI,我們的AI大腦(Ollama)在哪裡。
步驟 5:準備資料進行 RAG – 餵養AI「獨家秘笈」 #
這一步是RAG系統的核心!我們要將研華AIR系列的相關產品文件作為「獨家秘笈」餵給AI。
5.1 建立知識庫並上傳資料 #
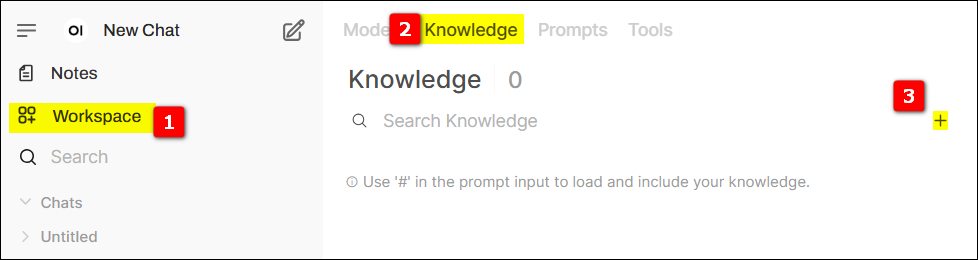
-
切換到知識庫頁面,點擊最右側的 + 號,建立新的知識庫。
-
給定該知識庫的相關資訊,與設定該知識庫的存取權限。
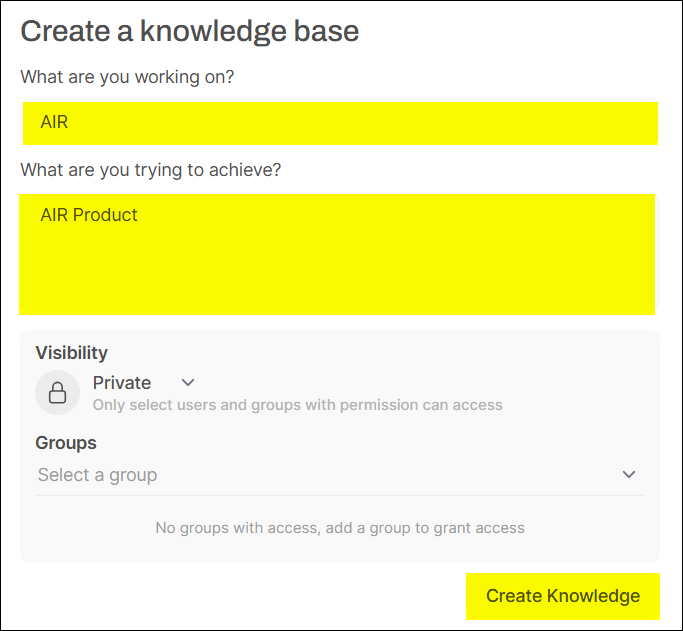
-
在新建的知識庫,點擊右側 + 上傳相關資料 (這裡我們使用的是研華 AIR Dataset)。
bge-m3模型將文件內容轉換成向量,存入向量資料庫,方便後續快速檢索。) -
切換到模型頁面,點擊最右側 + 號,新建一個模型。
-
給定相關的資訊,例如 Model Name (我們取名為
air-master),選擇 Base Model (Gemma3),最重要的是,選定我們剛剛建立的知識庫。這樣,這個air-master模型就和我們的AIR產品知識庫綁定啦!
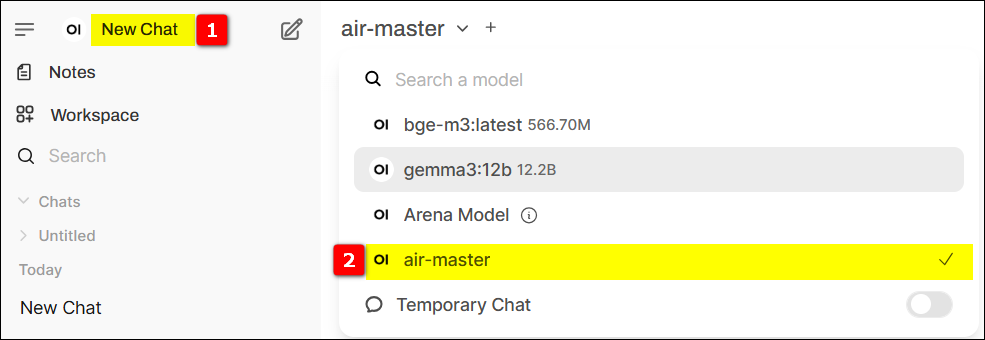
5.2 選擇模型進行問答測試 – 見證奇蹟的時刻! #
在 New Chat 進行問答測測試,選擇上一個步驟建立的 model (air-master)。
步驟 6:自動化驗證問答系統 – 讓AI接受「期末考」 #
為了確保我們的RAG系統不僅聰明,而且穩定可靠,工程師還準備了一套自動化測試腳本。
6.1 檢查 Firefox 瀏覽器 #
自動化腳本需要透過瀏覽器與OpenWebUI互動,因此需要確保Firefox瀏覽器安裝正確。
# 啟動 Firefox 後,執行以下命令
ps -aux | grep firefox
輸出解釋:
- Snap 版本:路徑包含 /snap/firefox
- DEB 安裝:路徑指向 /usr/lib/firefox/firefox
若為 snap 版本,需要先解除安裝 Firefox,然後建議使用 deb 方式安裝 Firefox:
# 解除安裝 Firefox
sudo snap remove firefox
sudo apt remove --purge firefox
# 使用 .deb 安裝 Firefox ,參考連結:
# https://support.mozilla.org/en-US/kb/install-firefox-linux?_gl=1%2A1ju8e27%2A_ga%2AMjk2NDkxMzMzLjE3Mzc4NzEzNTg.%2A_ga_MQ7767QQQW%2AMTczODc0ODU3Ny4xLjEuMTczODc0ODY2NS4wLjAuMA..
6.2 下載測試材料 #
下載自動化詢問 腳本檔案 並解壓縮。
解壓後包含以下幾個部分:
- config.ini:配置問答系統的 URL、帳密、模型和問題等。
- update_firefox:更新 Firefox 並下載最新版的 GeckoDriver 並解壓到當前路徑。
- UIQueAndAns1:執行該檔案後,自動開始問答。
- stop_UIQueAndAns1.sh:右鍵點擊或執行
./stop_UIQueAndAns1.sh停止問答,Firefox 瀏覽器不會關閉。
6.3 下載 GeckoDriver #
GeckoDriver 是 WebDriver 的一部分,能讓自動化腳本控制 Firefox 瀏覽器。
方式一:執行 update_firefox 腳本下載 GeckoDriver 並解壓到當前路徑。
方式二:透過網址 https://github.com/mozilla/geckodriver/releases 下載最新版的 GeckoDriver。
6.4 修改 config.ini 檔案 #
這個設定檔包含了測試用的問題,以及OpenWebUI的登入資訊。
[settings]
url = http://127.0.0.1:8080/
account = root@advantech.com.tw
psw = P@ssw0rd
[model]
model = air-master
[poch1]
q1 = What are the benefits of Advantech's certification service?
q2 = How does Advantech streamline IEC 62443-4-2 certification? Please list the key offerings.
q3 = How can Advantech's IEC 62443 certification service help meet the EU Cyber Resilience Act (CRA) requirements?
q4 = How do TPM 2.0 and BitLocker work together to enhance system security?
q5 = What is the purpose of Advantech Powersuite for security configuration?
[poch2]
q1 = I'd like to learn more about the Advantech AIR series.
q2 = Which AIR product supports an MXM GPU card?
q3 = Which AIR product comes with a built-in Hailo-8 AI accelerator?
q4 = Which AIR products use an NVIDIA Jetson module, and in addition, which AIR products are NVIDIA Certified?
q5 = Suggest an AIR solution featuring Advantech software that focuses on LLM fine-tuning tasks.
說明:
- [settings]-url:伺服器的 URL
- [settings]-account:使用者名稱
- [settings]-psw:系統登入的密碼
- [model]-model:問答時需要選擇的模型 (就是我們前面建立的
air-master) - [poch1] & [poch2]:預設的兩輪問答,包含了一系列關於研華產品和服務的問題。
6.5 執行腳本 #
右鍵點擊或執行 ./UIQueAndAns1 運行腳本。
腳本會自動打開Firefox,登入OpenWebUI,選擇air-master模型,然後逐一提出config.ini中設定的問題,並記錄AI的回答。這就像一場嚴格的考試,檢驗AI是否能準確理解問題並從知識庫中找到正確答案。
成果斐然:研華AI實力再升級! #
透過這次實戰,我們成功在研華 AIR-310 平台上,利用 OpenWebUI 和 Ollama 搭建了一個功能完善的RAG問答系統。這個系統能夠:
- 整合特定知識:有效地將研華AIR系列的產品文件轉化為AI可用的知識庫。
- 提供精準回答:針對特定問題,從知識庫中檢索相關資訊,生成比通用LLM更準確、更具體的答案。
- 易於操作與驗證:藉由OpenWebUI的友善介面和自動化測試腳本,簡化了系統的操作與驗證流程。
這項技術的突破,對於研華自身而言,意味著我們有能力打造更智能的內部知識管理工具,提升員工獲取資訊的效率;對於我們的客戶和合作夥伴而言,則展示了研華硬體平台在AI應用上的強大潛力。想像一下,未來您的設備手冊、技術支援文件、甚至客戶常見問題,都可以透過這樣的RAG系統,轉化為一個7x24小時不打烊的智能專家!
與傳統的關鍵字搜尋相比,RAG系統能更好地理解問題的語義,即使提問方式不同,只要核心意義相符,AI都能找到相關答案。這無疑是資訊檢索領域的一大步。
結論與未來展望:AI創新,研華永不止步! #
這次在 AIR-310 上成功構建並驗證RAG系統,不僅是研華工程團隊技術實力的一次精彩展現,更彰顯了我們在AI領域持續投入研發、積極擁抱創新的決心。
我們深知,AI的發展日新月異,今天的突破只是未來無限可能的一個起點。未來,研華將繼續探索:
- 更先進的模型:導入更強大、更高效的語言模型與嵌入模型。
- 更複雜的知識庫:處理更多元、更結構化的企業數據。
- 更廣泛的應用場景:將RAG技術拓展到工業物聯網、智慧醫療、智慧城市等更多垂直領域,為客戶創造實質價值。
- 更優化的邊緣部署:持續優化AI模型在研華邊緣運算平台上的效能,實現更低延遲、更高效率的邊緣智能。
研華相信,AI的力量在於應用,在於解決真實世界的問題。我們樂於分享我們的研究成果,並期待與更多夥伴攜手,共同探索AI技術的邊疆,開創智慧化的美好未來。如果您對我們的AI解決方案感興趣,或是有任何創新的想法,歡迎隨時與我們聯繫!讓我們一起,用AI點亮智慧的火花!