Have you ever wondered how to make AI models learn your specific tasks with fewer resources and at a faster pace? Today, let’s take a deep dive into the latest experiment from the Advantech team: using the Unsloth framework for LoRA (Low-Rank Adaptation) fine-tuning. Discover how to easily harness large language models (LLMs) and supercharge your AI’s capabilities!
Unsloth LoRA: The “Effort-Saving” New Choice for AI Fine-Tuning #
In the world of AI development, “bigger” has always been the trend—larger models and more complex computations, but this also means higher costs and resource consumption. LoRA fine-tuning technology is the key to overcoming this challenge! By adjusting only a small fraction of model parameters, LoRA enables rapid adaptation to new tasks, saving both time and effort. The Unsloth framework takes this technology to new heights, making the fine-tuning process faster, more stable, and more flexible.
Extensive Application Scenarios:
Whether it’s customer service conversations, smart healthcare, financial consulting, or industry-specific Q&A, whenever you need AI to “tailor” its performance based on proprietary data, LoRA fine-tuning is your best partner!
Key Parameters Revealed: Master Fine-Tuning Performance, Resources, and Results #
Think fine-tuning is as easy as pressing “start”? In fact, there are many important details behind the scenes! Let’s take a look at the key parameter designs from our experiment to help you get started quickly and achieve twice the results with half the effort:
1. Basic Options #
- Batch Size #
- How much data is processed at once? Unsloth optimizes memory usage, allowing you to set a larger batch size for more stable and efficient training.
- Maximum Sequence Length #
- How long can the model “see” at once? Unsloth handles long-form inputs with ease, so your model is no longer “memory-challenged.”
- Learning Rate #
- How big is each adjustment step? With LoRA, you can set a slightly higher learning rate than traditional full-parameter fine-tuning (e.g., $2e-4$ to $1e-3$) to accelerate learning. Just be careful not to set it too high, which could cause instability.
- Epoch #
- How many rounds of learning? LoRA’s reduced parameter count means faster training, so fewer epochs are typically needed. However, watch out for overfitting—use a validation set and early stopping for best results.
2. Advanced Options—LoRA-Specific Parameters #
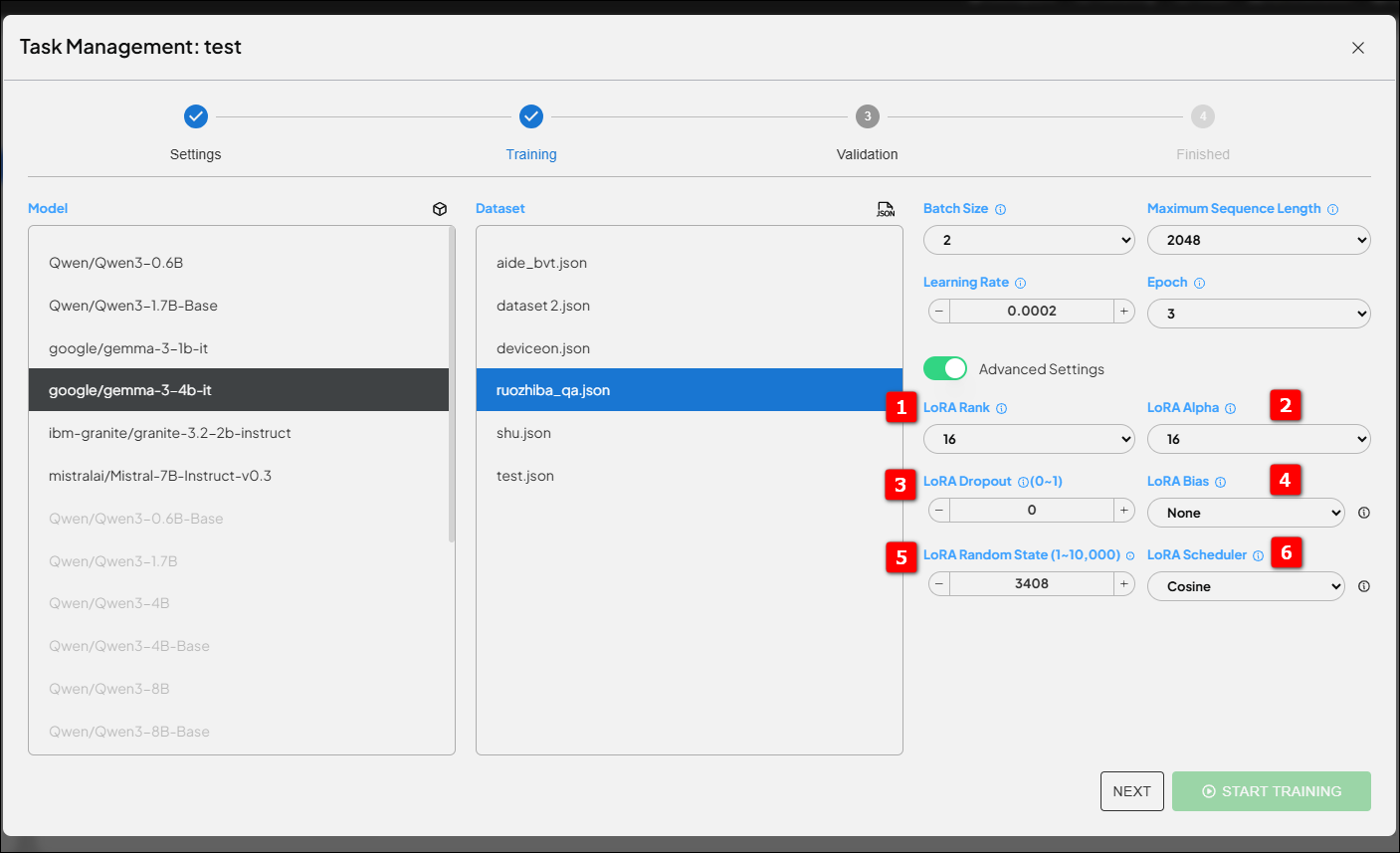
- 1. LoRA Rank (r) #
- Determines the “capacity” of the adaptation layer. Higher rank means more flexibility but greater resource consumption; lower rank is lightweight and efficient but with limited learning capacity. Recommended starting values: 16, 32, 64.
- 2. LoRA Alpha ($\alpha$) #
- Adjusts the learning amplitude, affecting learning rate and stability. The general recommendation is $\alpha = 2 \times \text{Rank}$, scaling proportionally with Rank to ensure the model learns neither too aggressively nor too slowly.
- 3. LoRA Dropout #
- Randomly disables some parameters to prevent the model from memorizing training data. Recommended value: 0.1. Use a slightly higher value for small datasets, or lower it when you have plenty of data.
- 4. LoRA Bias #
- Should model biases be adjusted? In most cases, choose None to maintain LoRA’s streamlined design.
- 5. LoRA Random State #
- Need reproducible results? Set a fixed number! Want to explore multiple possibilities? Randomize for broader exploration.
- 6. LoRA Scheduler #
- How does the learning rate change during training? Recommended schedulers include Linear (linear decay), Cosine (cosine decay), and Constant with Warmup (warmup then constant), all helping the model converge stably.
Adjusting LoRA Parameters for Different Datasets: Practical Advice from Advantech Engineers #
Small Datasets (Hundreds to Thousands of Samples) #
- Focus: Prevent Overfitting!
- LoRA Rank: 8, 16
- Dropout: 0.1~0.2
- Learning Rate: $1e-4$~$3e-4$
- Epoch: Can be higher, but always use a validation set and early stopping
Large Datasets (Tens of Thousands to Millions of Samples) #
- Focus: Training Efficiency and Performance!
- LoRA Rank: 32, 64, or even 128
- Dropout: 0.05 or 0
- Learning Rate: $3e-4$~$5e-4$
- Epoch: 1~3, paired with a learning rate scheduler
Datasets with Varying Text Lengths #
- Focus: Flexible Sequence Length and Batch Size Adjustment!
- Sequence Length: Refer to the 90th or 95th percentile of your data distribution (e.g., 1024, 2048)
- Batch Size: Adjust according to available memory; reduce batch size for long texts
Specialized/Domain-Specific Datasets #
- Focus: Give the Model Sufficient Expressiveness to Learn New Knowledge!
- LoRA Rank: 32 or 64
- Learning Rate: Lower it if convergence is difficult
Advantech’s Technological Innovation Empowers AI to Understand You Better! #
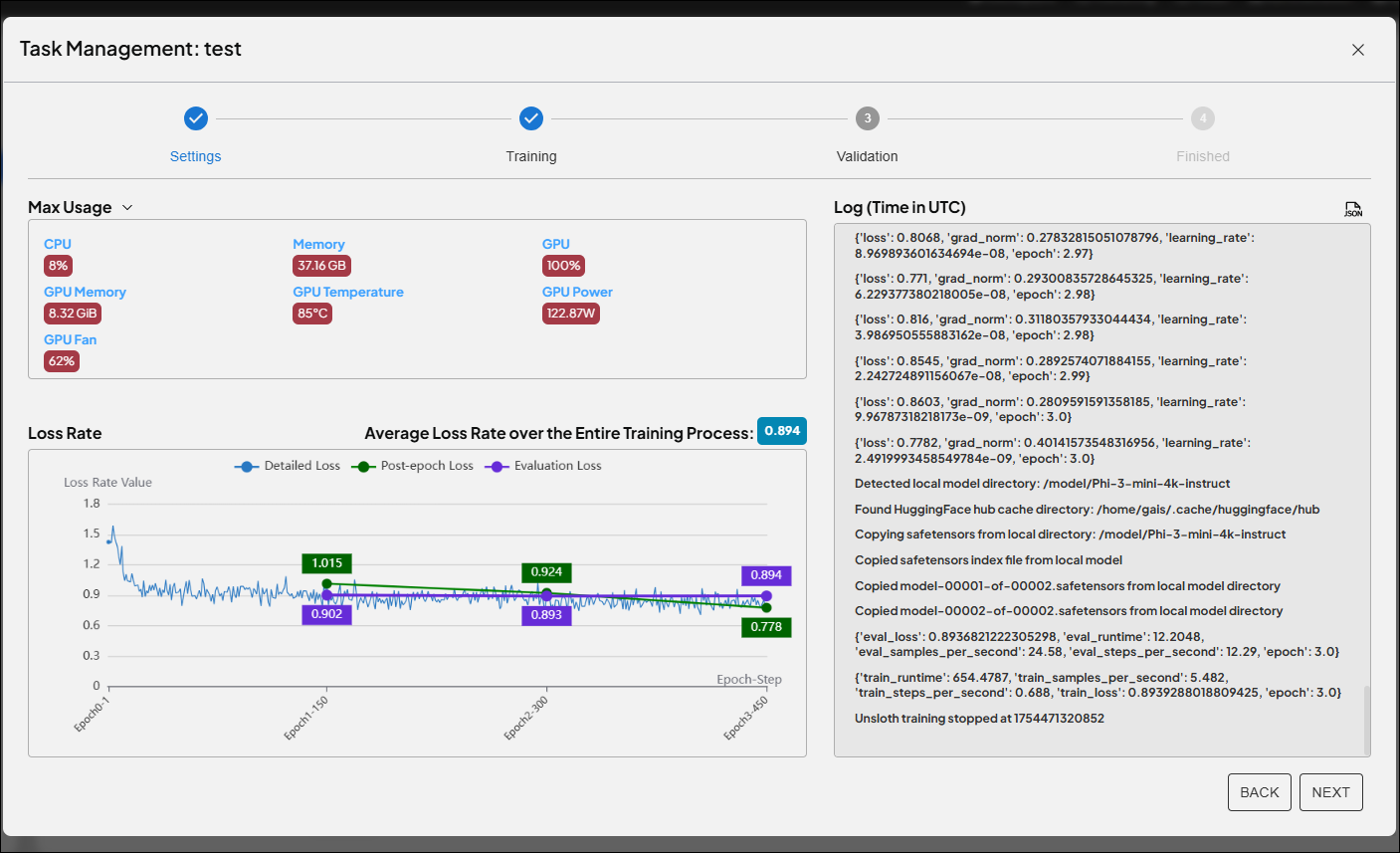
This experiment proves that Unsloth LoRA can not only significantly enhance AI fine-tuning efficiency, but also flexibly adapt to various data scales and industry requirements. Fine-tuning key parameters such as LoRA Rank and Alpha is the secret weapon to unlocking your AI’s potential. More importantly, the Advantech team is committed to ongoing core AI technology R&D, driving digital transformation and intelligent upgrades across industries.
Looking ahead, we will continue to explore more efficient and smarter fine-tuning techniques, working hand in hand with our clients to create tailor-made intelligent applications—making AI truly deliver value. If you’re interested in AI fine-tuning or intelligent applications, feel free to connect with us. The next innovation breakthrough could be our shared story!
Summary Tips:
- LoRA fine-tuning = efficiency upgrade; the Unsloth framework helps you save, save, save on resources!
- Parameter settings require expertise—experimentation and monitoring are key for optimal results.
- Advantech continues to innovate, helping your AI applications stay ahead of the curve!
(For in-depth discussions or to experience more technical details, please contact the Advantech professional team!)