Background Story: Fine-Tuning AI for True Domain Understanding #
As generative AI sweeps across the globe, enterprises are no longer satisfied with generic AI models—they seek language models that are “closer to their business and industry.” This is where “fine-tuning” comes in: adjusting model parameters based on specific datasets so that AI can learn industry-specific knowledge and language styles. Think of it as giving AI an advanced course to transform it into your company’s most powerful knowledge partner.
But fine-tuning isn’t as simple as feeding data and pressing start. The key to model performance lies in how you set these four core parameters: batch size, maximum sequence length, learning rate, and training epochs. Adjusting these parameters not only affects training efficiency and results but also determines whether your AI can truly “learn well and last long”!
The Four Core Parameters: Master the Essentials of AI Fine-Tuning #
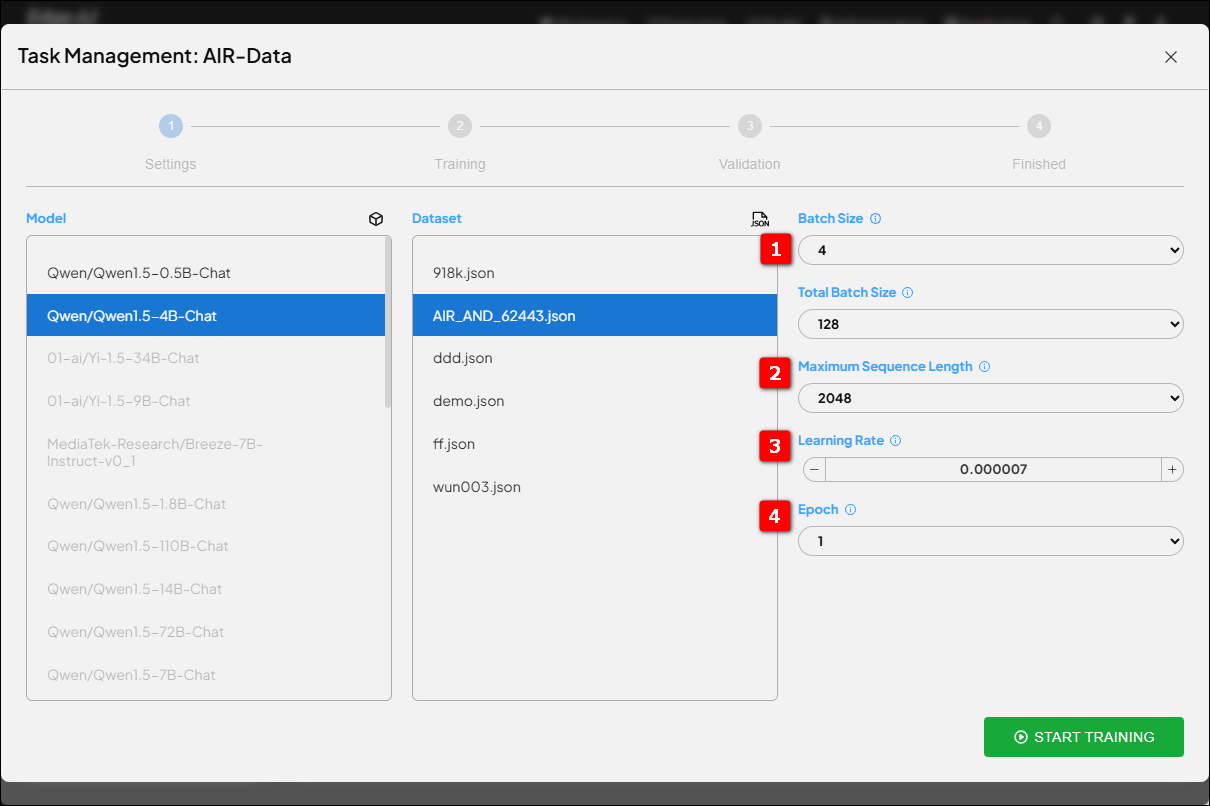
1. Batch Size: How Much Data Should the AI Process at Once? #
Imagine reading a book—how many pages do you read before summarizing? That’s the concept of batch size. If set too small, learning becomes unstable and inefficient; too large, and your memory resources are overwhelmed, potentially missing out on key insights. Especially in multi-GPU training, the total batch size (sum across all GPUs) is crucial for training stability.
- Too small: Unstable learning, slow progress
- Too large: VRAM overload, risk of getting “stuck”
- Remember: Hardware limitations are the deciding factor!
2. Maximum Sequence Length: How Much Can AI See at Once? #
This is like the length of an article you can read in one go. The longer the setting, the more complete the context AI can understand—but it also dramatically increases computation and memory usage. Too short, and important information gets cut off; too long, and you waste resources on unnecessary padding.
- Sufficient length: Complete context, ideal for long-text tasks
- Too short: Information loss
- Too long: Resource waste
3. Learning Rate: How Big Should Each Step Forward Be? #
Learning rate is like the size of each step you take toward a goal. Too large a stride, and you risk “overshooting” the optimal solution and unstable training; too small, and progress is slow, potentially getting stuck.
- Too high: AI skips too quickly, misses key points
- Too low: Like a turtle, may never reach the finish line
4. Epochs: How Many Times Should AI Review the Material? #
Each epoch is one full pass through the entire dataset. Too few, and learning is incomplete; too many, and the model memorizes instead of generalizes, struggling with new data (overfitting).
- Too few: Underfitting, can’t learn well
- Too many: Overfitting, rote memorization
- Pro tip: Use “early stopping” to achieve just the right amount of learning!
Experimental Monitoring: Keeping Track of AI’s Learning Performance! #
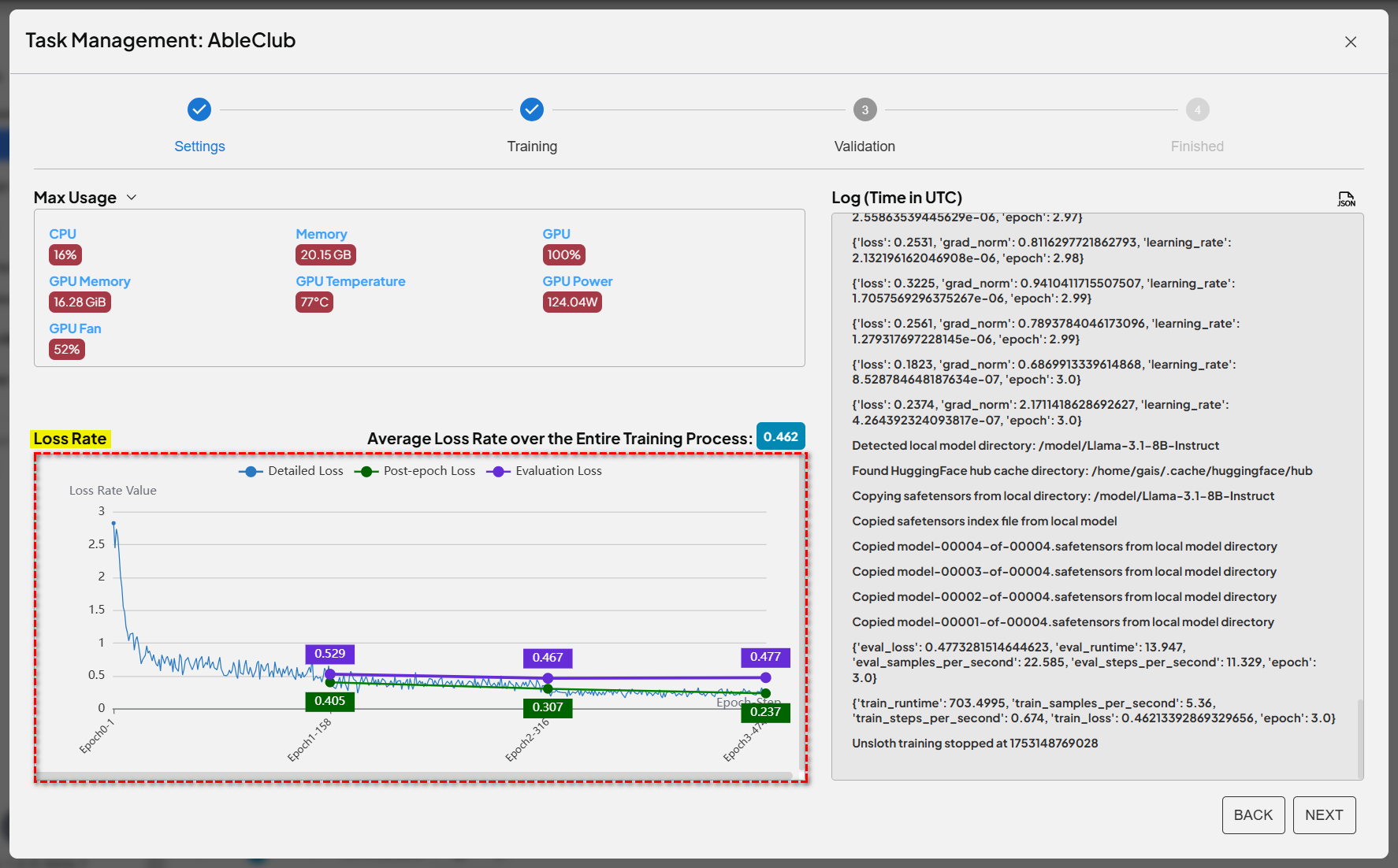
During experiments, our main focus is on two key metrics: “training loss” and “validation loss.” Think of these as AI’s report cards.
- Training loss: How well does AI perform on data it has seen? Lower is better.
- Validation loss: How well does AI perform on unseen data? This is the real test.
How to Interpret the Learning Curve? #
- Ideal scenario: Both losses decrease, small gap—AI is learning quickly and effectively.
- Overfitting warning: Training loss keeps dropping, but validation loss stalls or rises—AI is memorizing!
- Underfitting sign: Both losses remain high—AI hasn’t learned anything.
Practical Tuning Tips: Tailor the Best Recipe for Your Dataset #
In our lab, we constantly fine-tune and optimize to ensure every client and application gets the most suitable AI. Parameter adjustments depend heavily on dataset characteristics:
Small Datasets (Hundreds to Thousands of Samples) #
- Learning rate: Lower (1e-5 to 5e-6) to avoid instability
- Batch size: Smaller (4–16) for more varied samples per epoch
- Epochs: More passes (10+), but monitor validation loss and stop early as needed
Large Datasets (Tens of Thousands to Millions) #
- Learning rate: Can be higher (1e-5 to 5e-5) with a learning rate scheduler
- Batch size: Larger (32–128+) to maximize GPU utilization
- Epochs: Usually done within 10 epochs; focus on closely monitoring the loss curves
Variable Text Lengths #
- Maximum sequence length: Adjust based on actual statistics to avoid excessive padding or truncation
- Advanced tip: Use bucketing to process data in groups, saving resources
Domain-Specific Datasets (Medical, Legal, Code, etc.) #
- Learning rate: Even lower to let the model steadily absorb new knowledge
- Epochs: More patience needed for AI to deeply learn domain know-how
Advantech AI Lab’s Ongoing Innovation: AI Tailored for You #
Through this full-parameter fine-tuning experiment, we have not only validated the impact of each key parameter, but also established a scientific, replicable optimization process. This means whether you’re building a smart healthcare assistant, smart factory Q&A, or an industry-specific knowledge base, Advantech can tailor the optimal AI solution based on your data!
Our Innovation Highlights:
- Continuous optimization of parameter combinations for faster, more accurate learning
- Real-time monitoring of learning curves, intelligent adjustments to precisely prevent overfitting
- Deep industry expertise for rapid development of customized AI solutions
Conclusion & Future Outlook: No Universal Parameter, Only the Best Custom Solution #
AI fine-tuning is like crafting the perfect cup of coffee just for you. There’s no one-size-fits-all recipe—only by continuously optimizing and adjusting to your “taste” (dataset characteristics) and needs (application scenarios) can you develop the strongest AI partner!
Looking ahead, Advantech AI Lab will continue to advance fine-tuning technology, integrating automated monitoring and intelligent parameter recommendations to help enterprises rapidly implement tailored AI and seize new opportunities in digital transformation. Want to know how your AI can further evolve? Connect with us and witness the limitless possibilities of AI innovation together!
Key Reminders:
- There are no absolute standards for parameter tuning; dynamic optimization is needed based on data scale and application needs
- Continuously monitor loss curves and adapt to overfitting or underfitting
- Advantech’s extensive experience and innovative technology help you build the most suitable AI solutions
Want to learn more about parameter tuning, AI fine-tuning, or have any application needs? The Advantech AI team is always here to explore the latest in technology with you!