AI in Action! Easily Launch the DeepSeek-R1 Large Model with Advantech Jetson Orin
·loading
Author
Advantech ESS
Table of Contents
Table of Contents
Have you ever wondered if running the latest AI large models at lightning speed on an industrial-grade platform is really that out of reach? In this experiment, our team successfully ran the popular DeepSeek-R1 and various LLMs on Advantech’s latest Jetson Orin series platforms, bringing smart applications one step closer to reality! Join us as we witness a new breakthrough in AI technology together!
As AI becomes increasingly widespread, the demand for edge computing continues to rise. Whether in smart manufacturing, retail, transportation, or healthcare, real-time on-site inference and massive data processing are becoming critical. The NVIDIA Jetson Orin platform is renowned for its high performance and low power consumption, making it particularly suitable for deploying advanced AI applications. However, enabling large language models like DeepSeek-R1 to run smoothly on edge devices is not without its challenges. This experiment aims to verify and optimize this process, bringing AI truly to the field!
This means that from small to ultra-large LLMs, Advantech platforms are ready to go right out of the box!
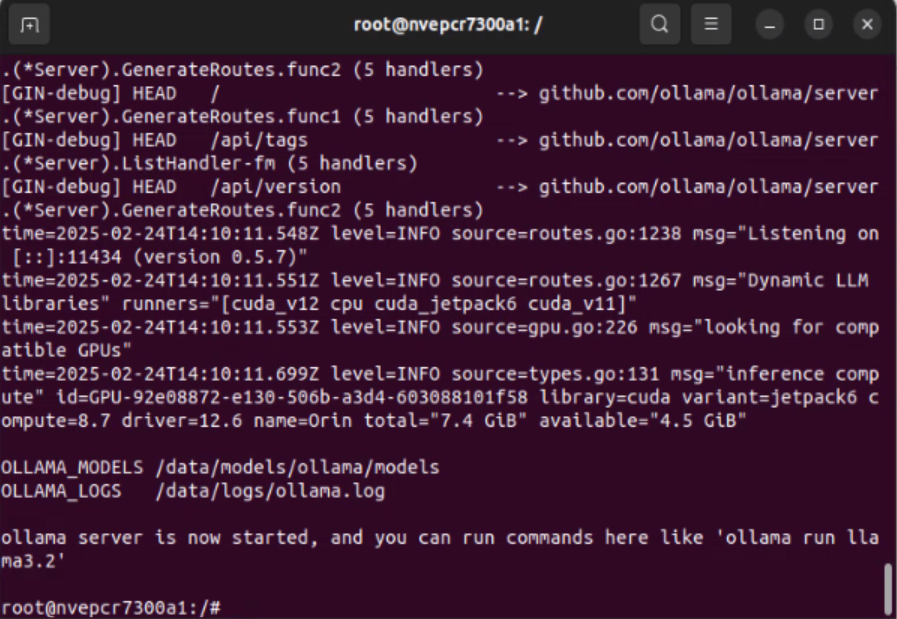
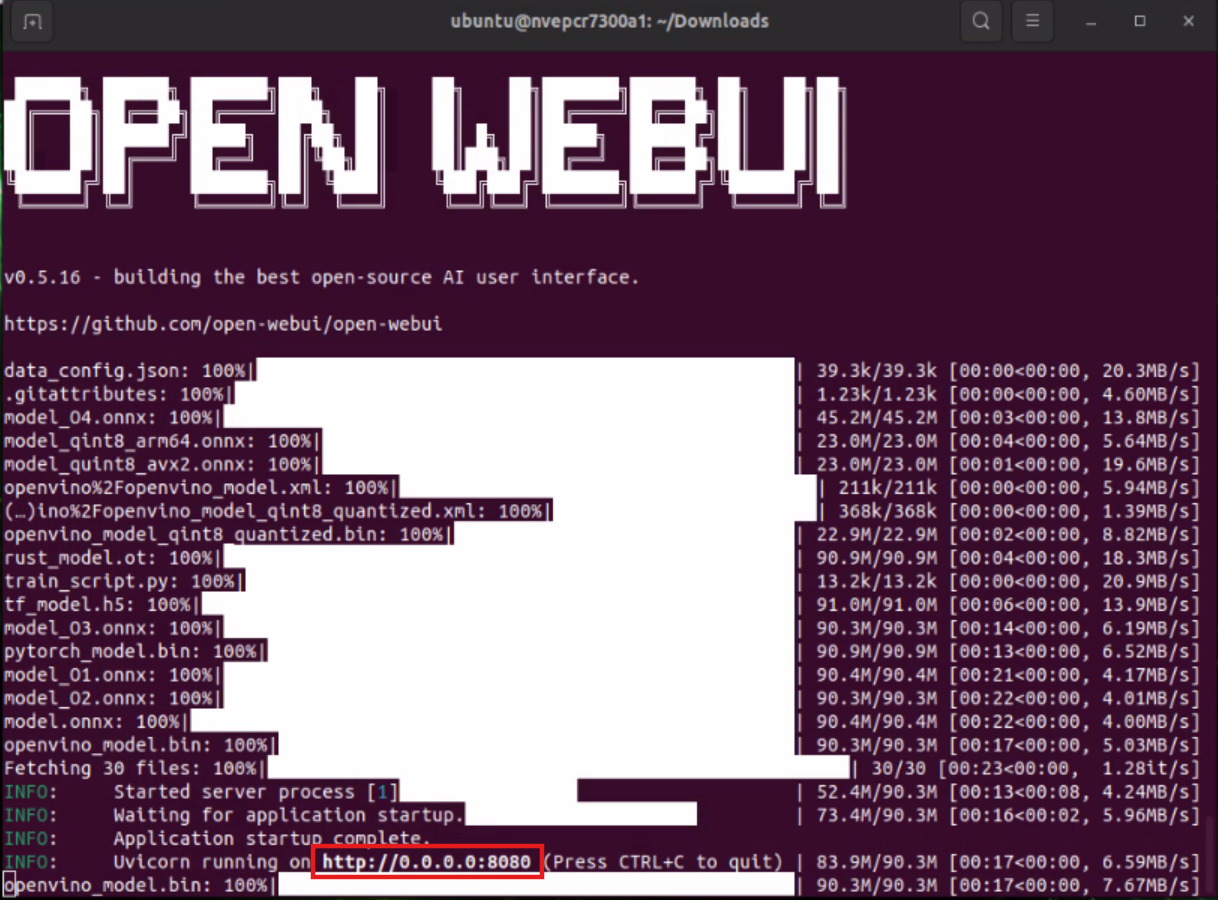
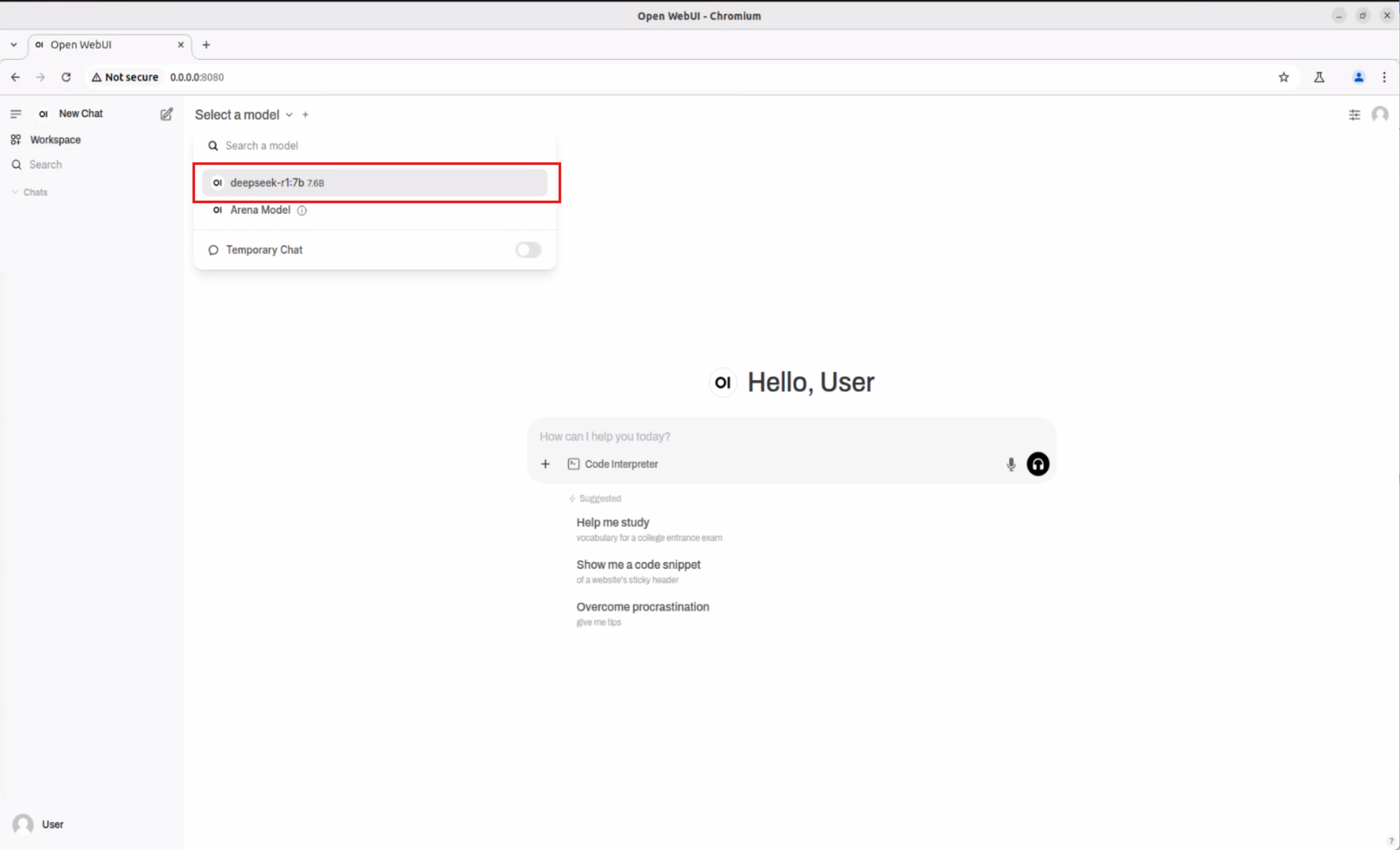
Full Experiment Workflow: Running AI Has Never Been Easier!
#
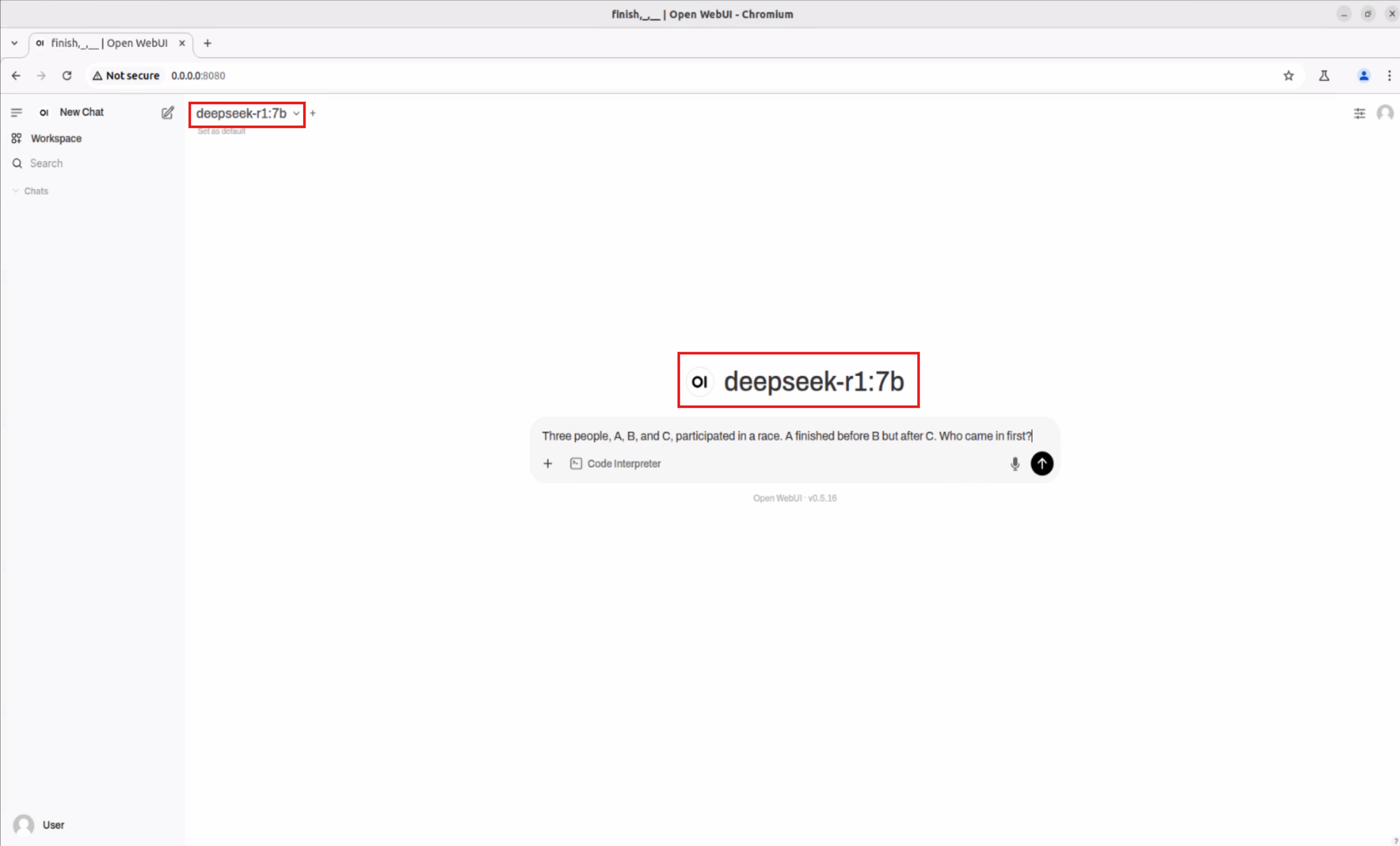
Imagine being able to achieve natural language conversations, mathematical reasoning, and a variety of professional applications on your own device in just a few steps. Below are the complete experimental steps—whether you are an engineer or a business partner, you can get started with ease!
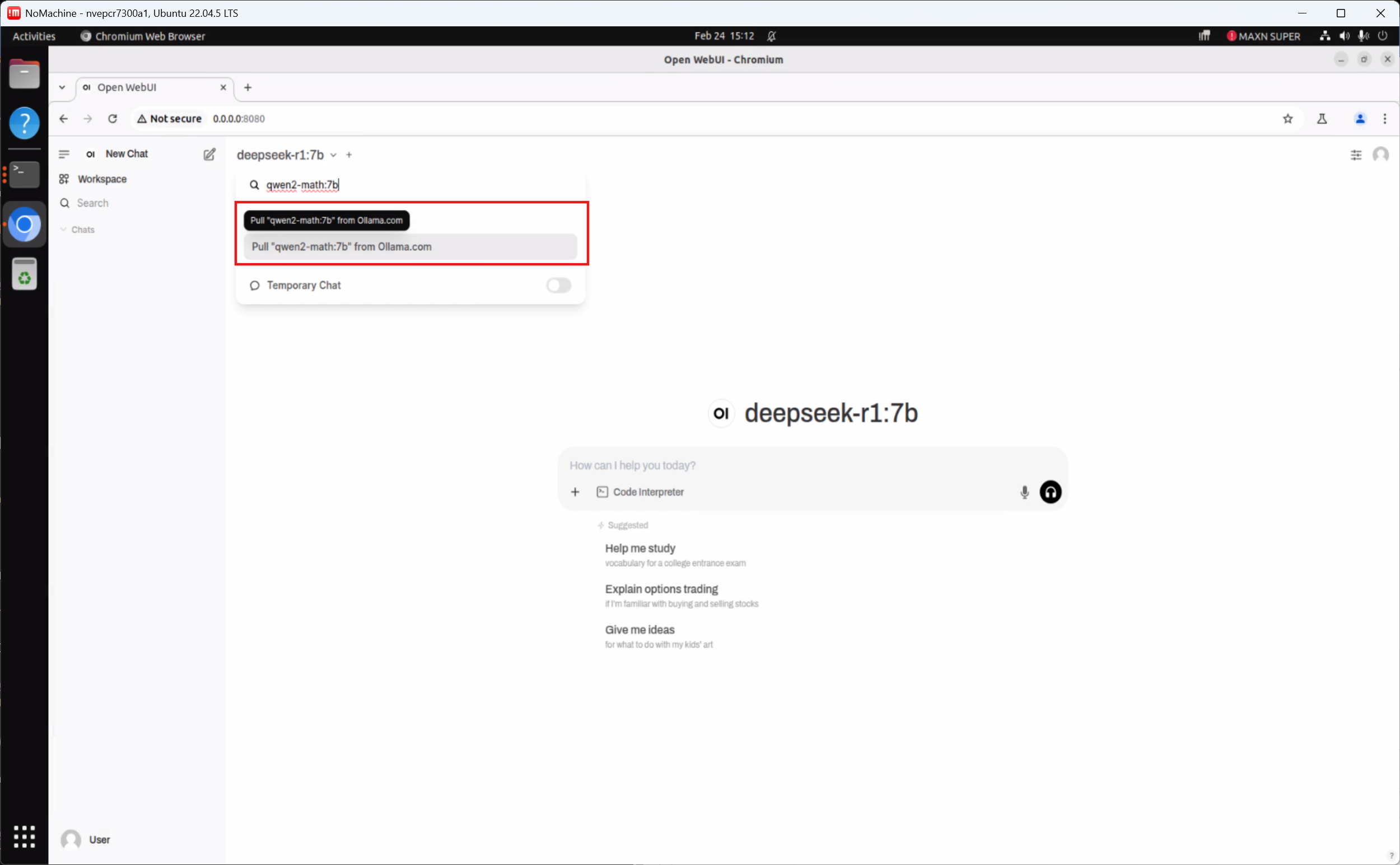
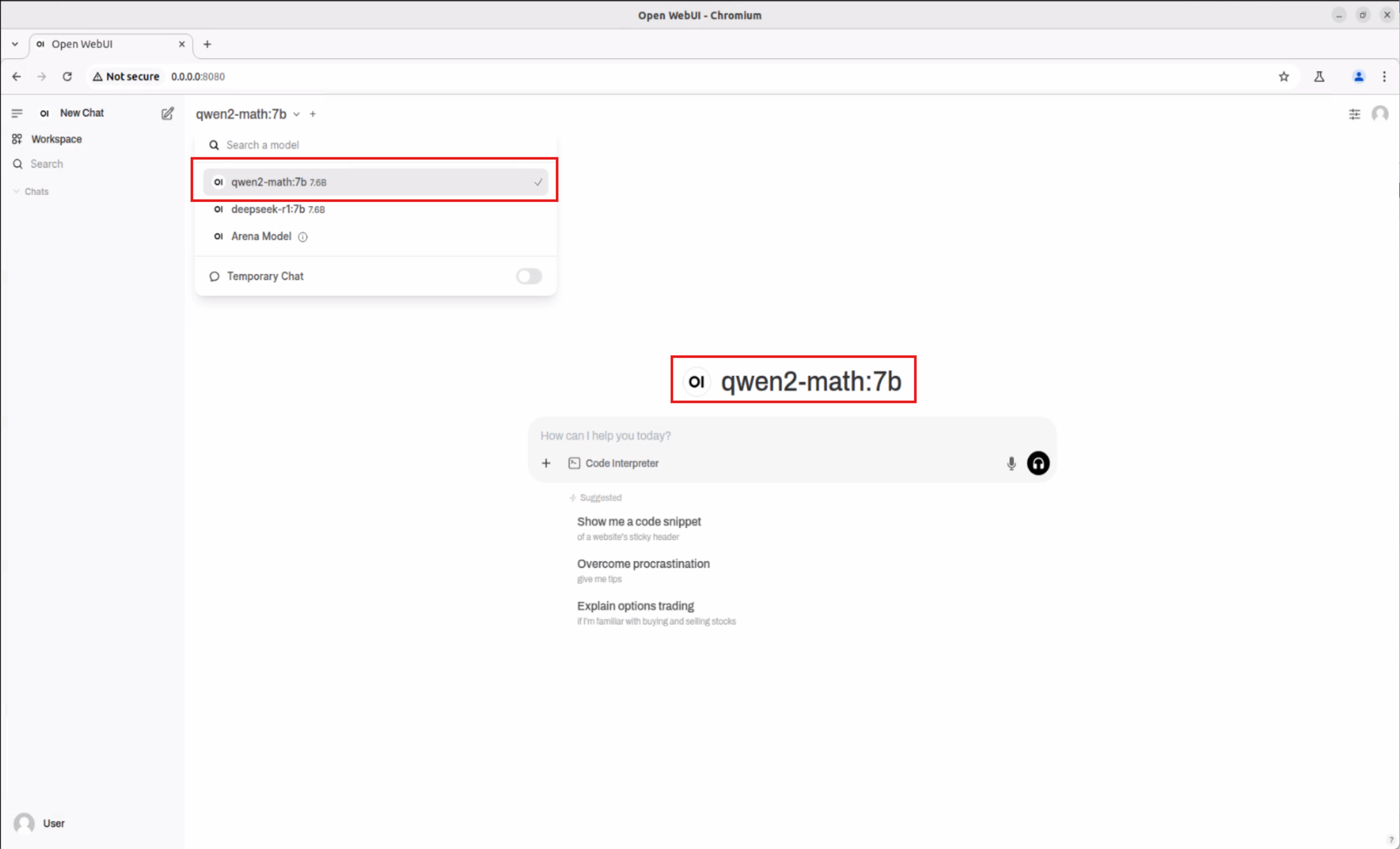
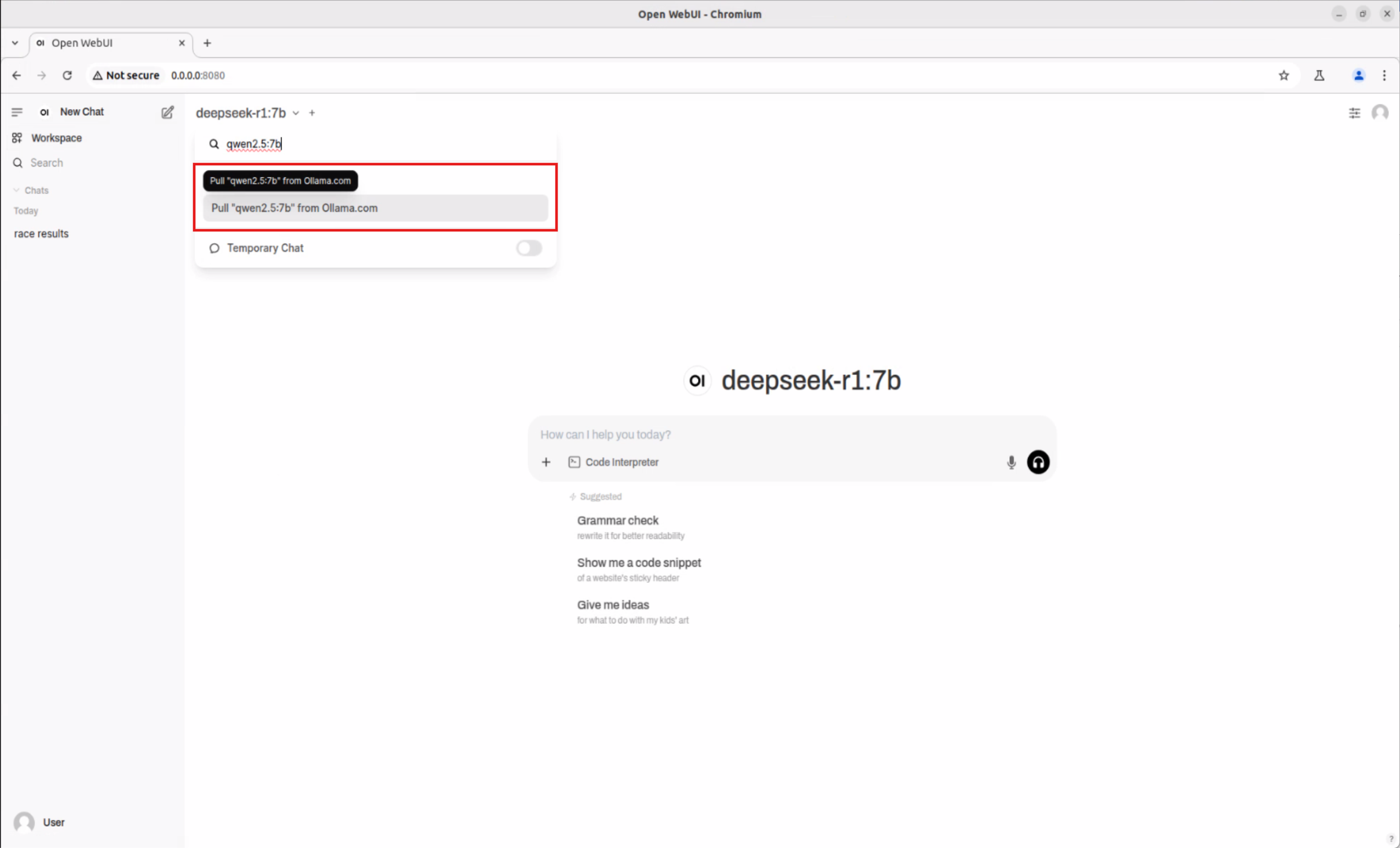
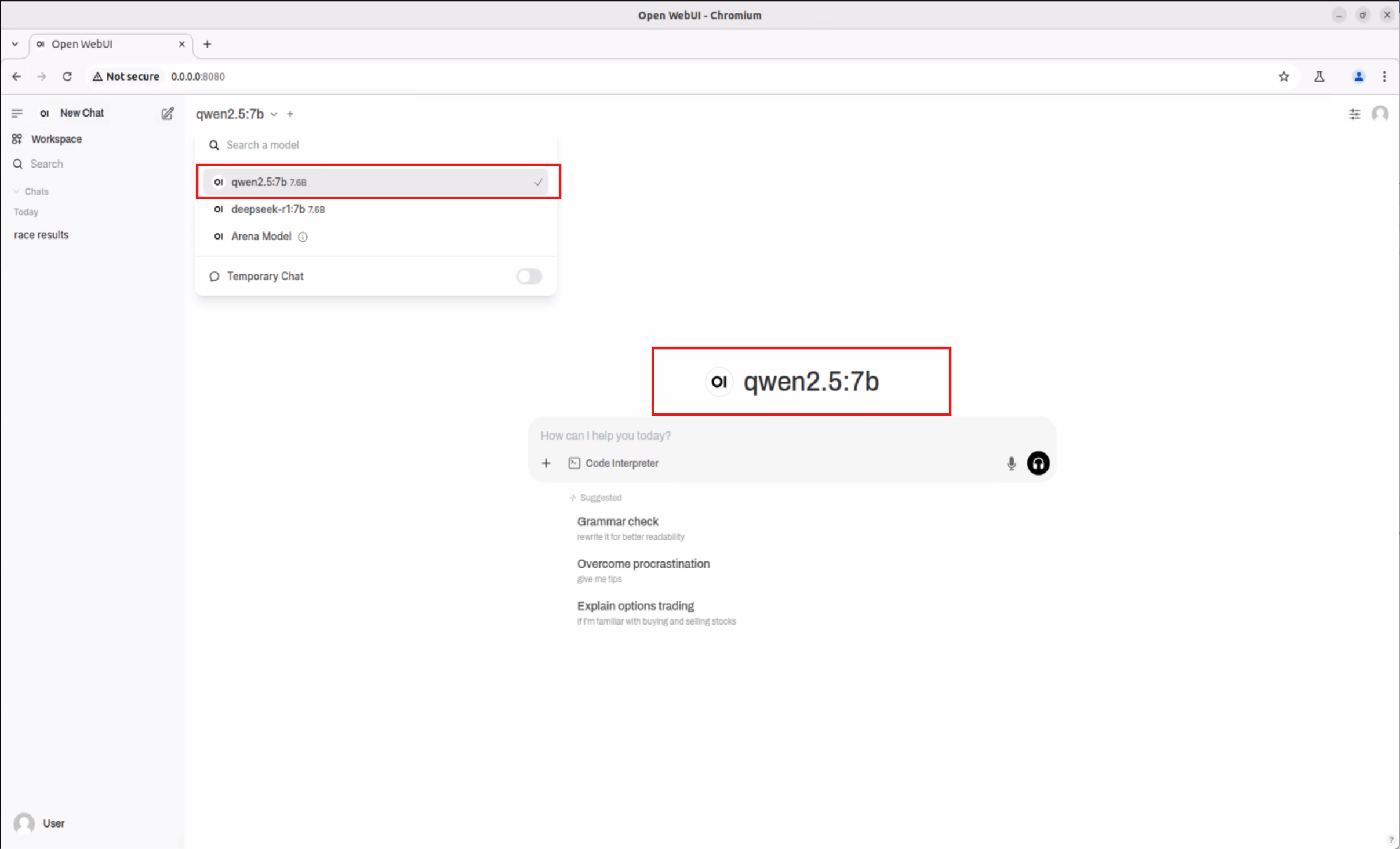
Follow the same process to download and use various AI models such as Qwen2.5-Math:7b, Qwen2.5:7b, supporting scenarios like mathematical reasoning and professional Q&A.
This experiment proves that the Advantech Jetson Orin platform not only supports a variety of mainstream large models (LLMs), but can also be easily deployed at the edge to enable:
Real-time voice/text analysis on smart factory floors
Automated response in retail/customer service
Smart medical information queries
Traffic monitoring and decision support
Automated data reasoning and knowledge management
Highlights:
No reliance on the cloud—every site can be AI-enabled in real time
Flexible support for multiple models, enabling rapid application switching
Open architecture for easy secondary development and integration
High performance and low power consumption, suitable for 24/7 operation
With a rigorous yet dynamic approach, the Advantech engineering team has demonstrated our continuous innovation and breakthroughs in the field of AI edge computing. Looking ahead, we will continue to optimize platform compatibility, track new models and inference architectures, and help customers quickly adopt cutting-edge AI technologies, seizing every digital transformation opportunity!
Advantech will continue to focus on innovation, making AI technology truly accessible and empowering smart upgrades across industries. To learn more about our latest experiments and solutions, feel free to contact us anytime!
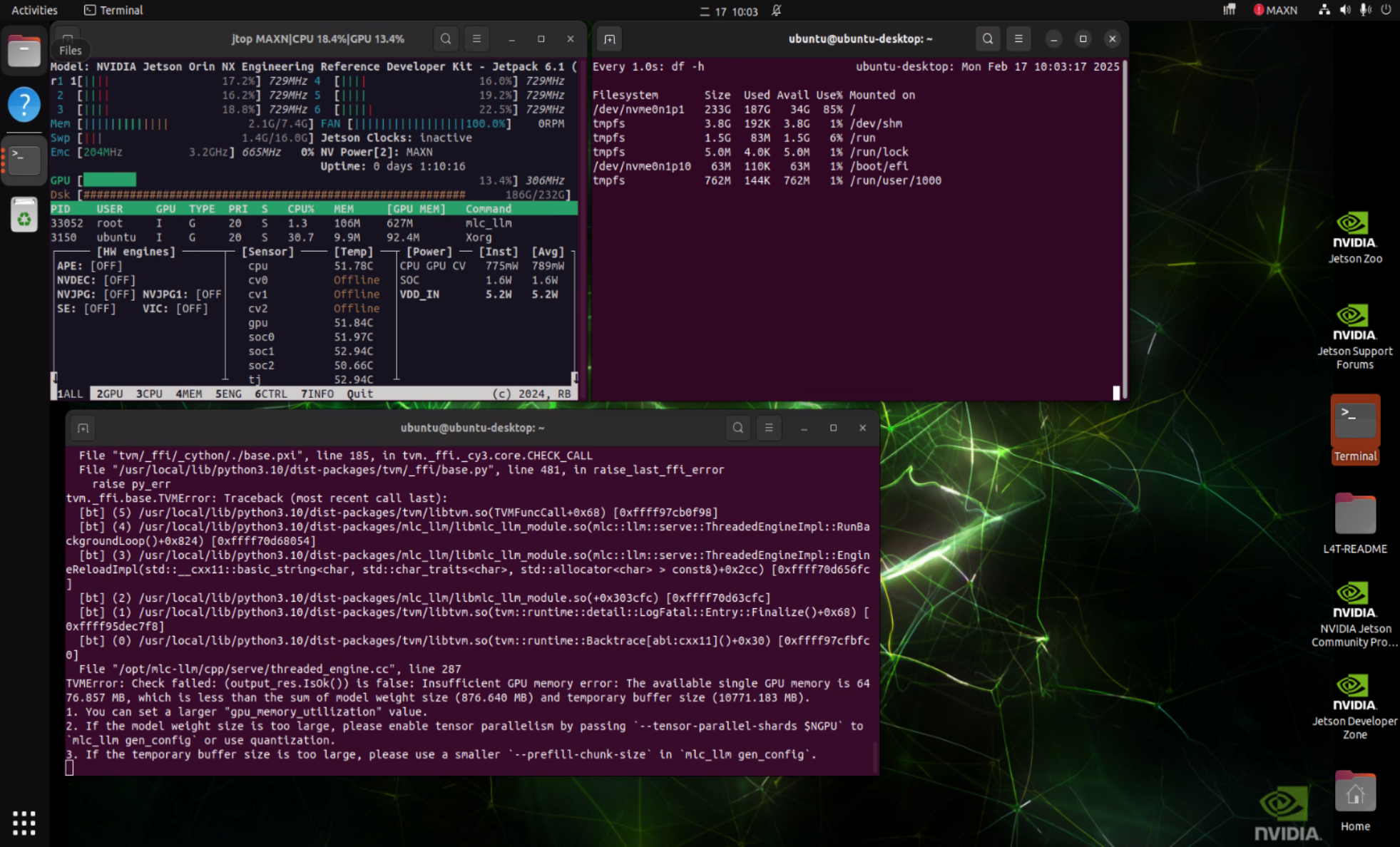
Reminder: Currently, when using Qwen architecture models with the MLC inference framework, you may encounter compatibility issues (as shown below). We are actively coordinating with NVIDIA to resolve this!