This article has been rewritten and reorganized using artificial intelligence (AI) based on referenced technical documentation. The purpose is to present the content in a clearer and more accessible manner. For technical clarifications or further verification, readers are advised to consult the original documentation or contact relevant technical personnel.
Hey there, friends curious about AI, and our most supportive AE and sales partners!
Imagine how exciting it would be if powerful AI language models were no longer confined to distant clouds, but could operate directly on devices right beside us? This would not only mean faster response times and higher data security but also unlock countless innovative application possibilities. This is the charm of edge AI, and the emergence of Large Language Models (LLMs) has pushed AI capabilities to new heights.
However, as you might know, full LLM models are typically very large and require significant computing resources. This is where “Small Language Models” (sLLMs) come into play! sLLMs are optimized, smaller language models designed specifically to run on resource-constrained edge devices. They retain many of the core capabilities of LLMs while significantly reducing hardware requirements.
At Advantech, we always stay at the forefront of technology, constantly exploring how to implement the latest AI technologies on our hardware platforms. Recently, our engineering team conducted an interesting experiment: running sLLM models like DeepSeek R1 on Advantech’s edge AI systems based on the NVIDIA Jetson Orin platform! The goal of this experiment was to verify whether our platform could smoothly and effectively execute these advanced sLLMs, laying a solid foundation for future edge AI applications.
Now, let’s dive into the exciting process of this experiment together!
The Experiment’s Stars: Advantech’s Jetson Orin Platforms #
The main characters of this experiment are two powerful edge AI platforms from Advantech based on NVIDIA Jetson Orin:
- EPC-R7300: Equipped with NVIDIA Jetson Orin Nano-Super (8GB), a compact yet powerful edge computer.
- AIR-030: Equipped with NVIDIA Jetson Orin AGX (32GB/64GB), offering more powerful AI computing capabilities.
Both platforms have the potential to execute complex AI tasks at the edge. In this experiment, we will deploy sLLM models on these platforms to see how they perform.
Getting Ready: Setting Up the Software Environment #
To run sLLMs on the Jetson Orin platform, some preliminary setup is required. Our engineers followed the official guidelines from NVIDIA Jetson AI Lab and performed the following key steps:
Installing Docker #
Docker is a very convenient containerization tool that helps us easily deploy and manage applications, including AI model runtime environments.
Refer to the official NVIDIA Jetson AI Lab installation link: https://www.jetson-ai-lab.com/tips_ssd-docker.html
Installing Jetson-containers #
jetson-containers is a collection of containers containing many common AI frameworks and tools, simplifying the process of deploying AI applications on the Jetson platform.
cd /home/ubuntu/Downloads
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
Disabling System Notifications (A Little Tip!) #
During the experiment, engineers found that system notifications might interfere with operations, so they disabled them. While this is a small detail, it also shows our effort in pursuing a smooth experience.
-
Disable warning pop-up windows.

-
Install dconf-editor using the following command:
sudo apt update sudo apt install dconf-editor -
After installation, you can use dconf-editor to modify system settings:
dconf-editor
-
Navigate through the directory levels according to the following path: /org/gnome/desktop/notifications/
-
Disable according to the diagram, and warning pop-up windows will be disabled.
Core Deployment: Ollama and Open WebUI #
To facilitate managing and interacting with sLLM models, we used Ollama and Open WebUI. Ollama is a lightweight framework that allows easy local execution of various open-source language models; Open WebUI provides a user-friendly web interface, allowing us to interact with models directly in the browser.
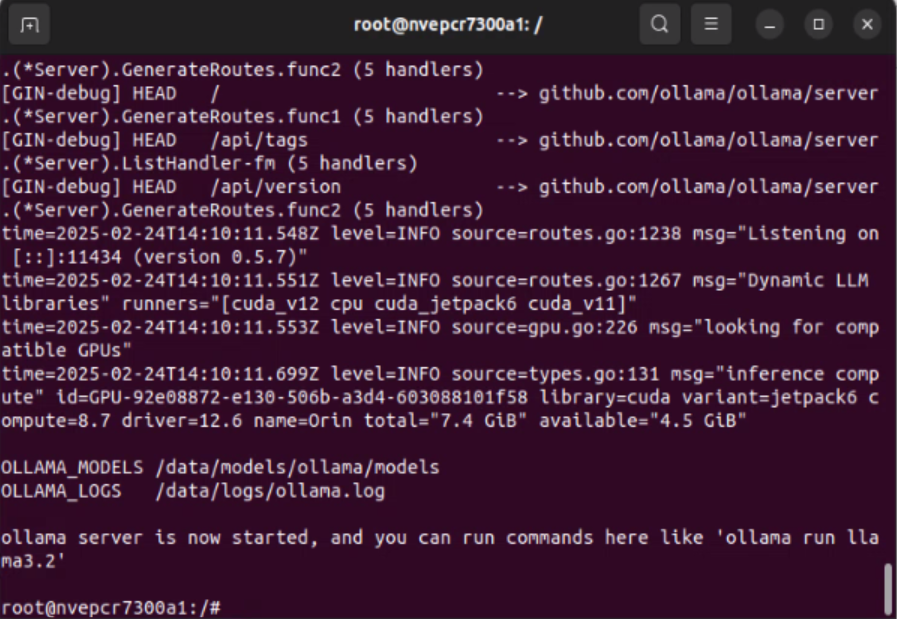
Launching the Ollama Docker Container #
jetson-containers run --name ollama dustynv/ollama:r36.4.0
Please keep the CMD window open after executing the command.
Launching Open WebUI #
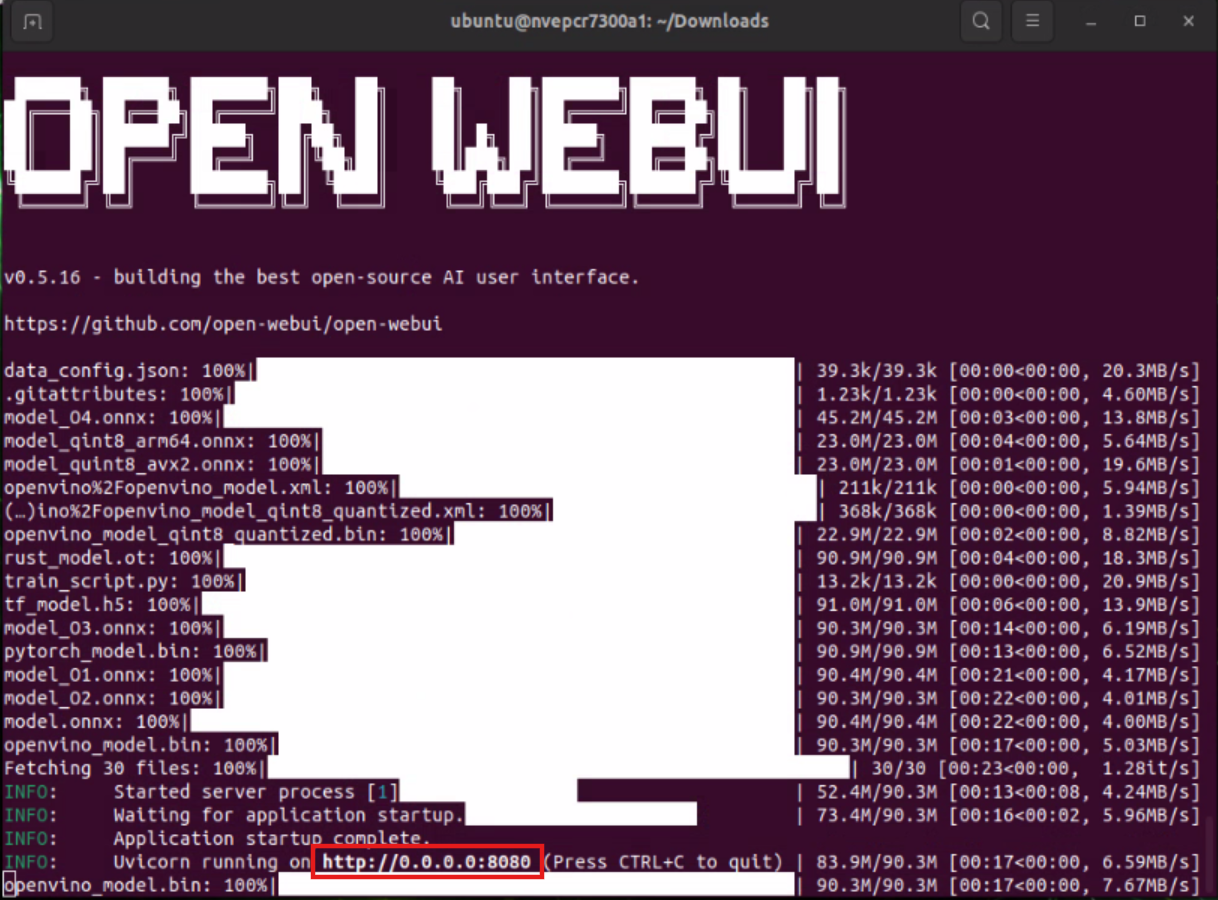
Open another CMD window. To run an Open WebUI server for client browsers to connect to, use the open-webui container:
docker run -it --rm --network=host -e WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
Please keep the CMD window open after executing the command.
Hands-on Experience: Interacting with sLLMs! #
After setting up the environment, the most anticipated part arrives: interacting with the DeepSeek R1 model through Open WebUI!
Basic Usage Steps #
Step 1. Access http://0.0.0.0:8080 via a web browser (Please refer to the CMD window above for the IP address) #
You will see the initial web page as shown below.
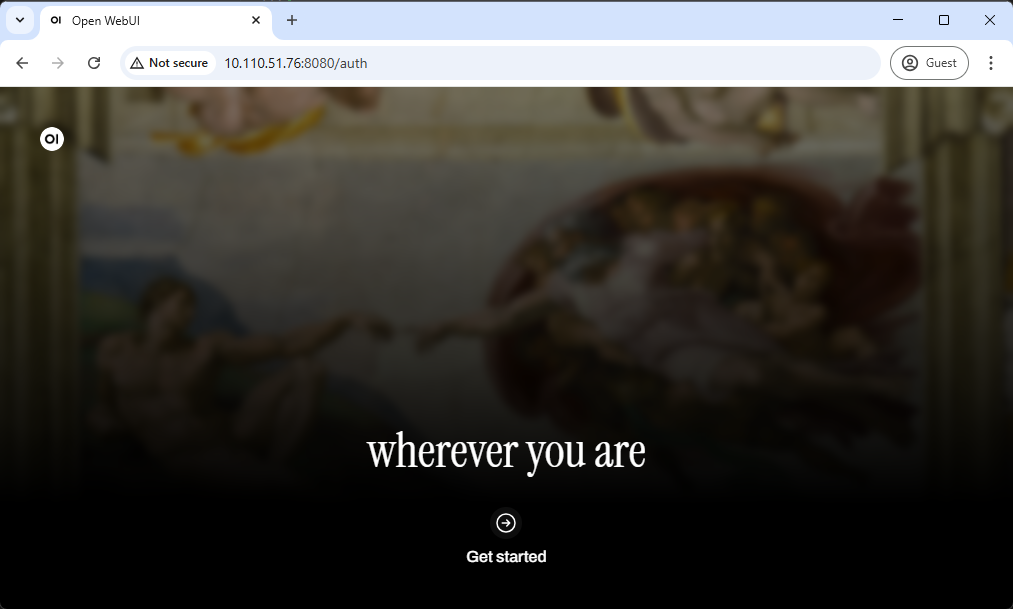
Click " Get started “.
Step 2. Click the " Okay, Let’s Go! " button to continue #

Once everything is set up, you should see the UI interface as shown below.
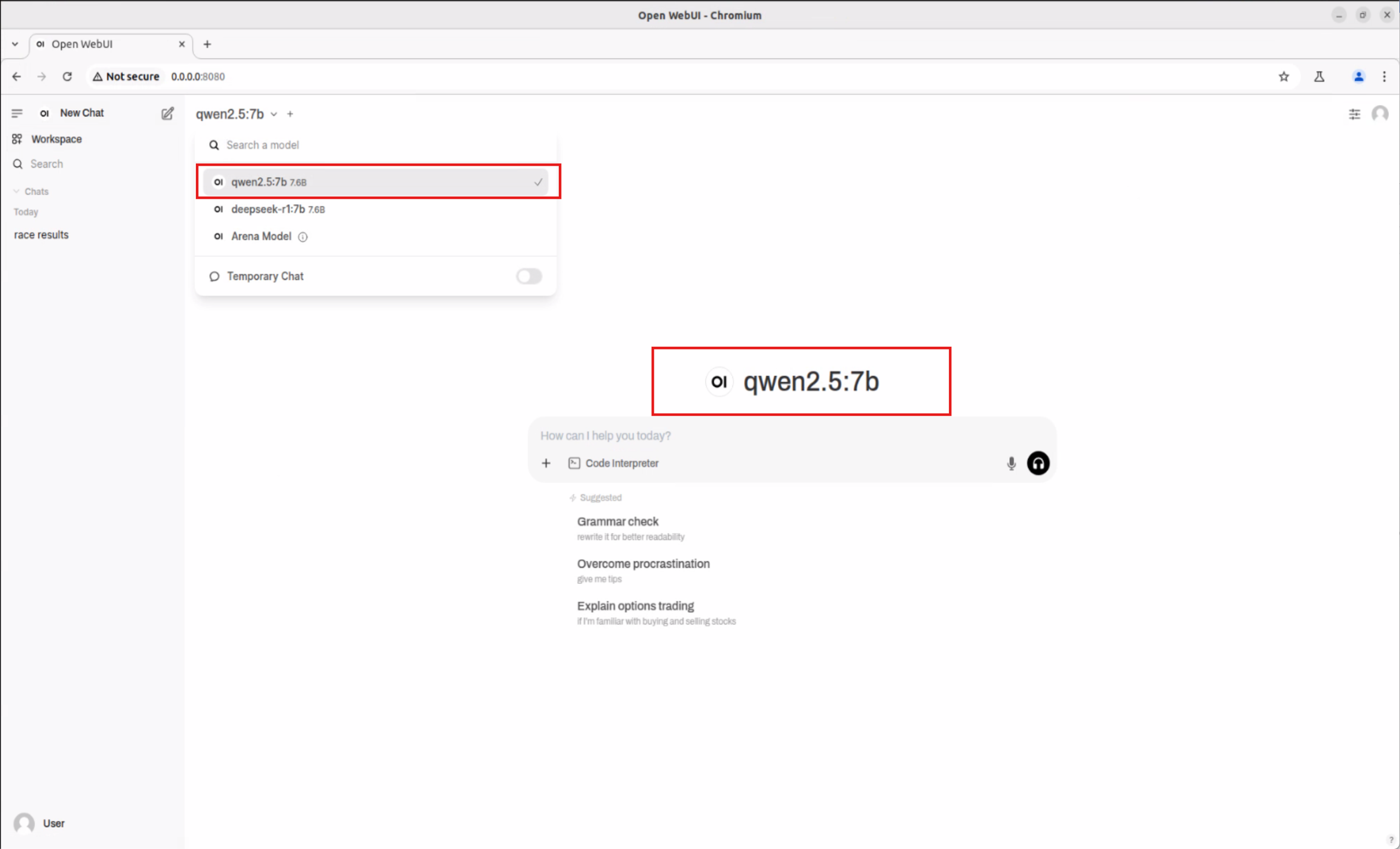
3. Download the deepseek-r1:7b (DeepSeek R1 Qwen-7B) Model #
To download the deepseek-r1:7b model, click the dropdown menu next to “Select a model”. In the “🔎 Search a model” field, enter the name of the model you want to try.
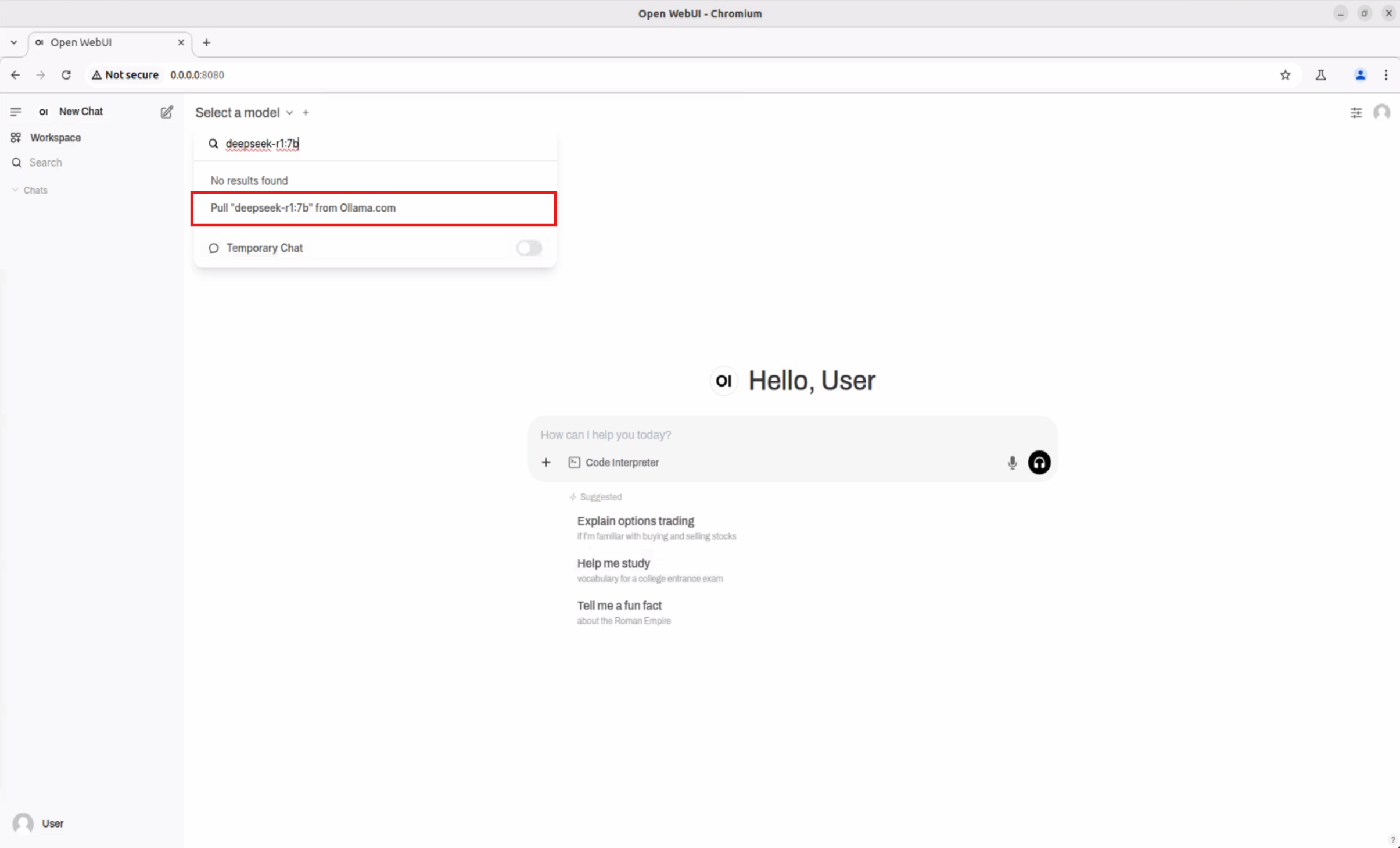
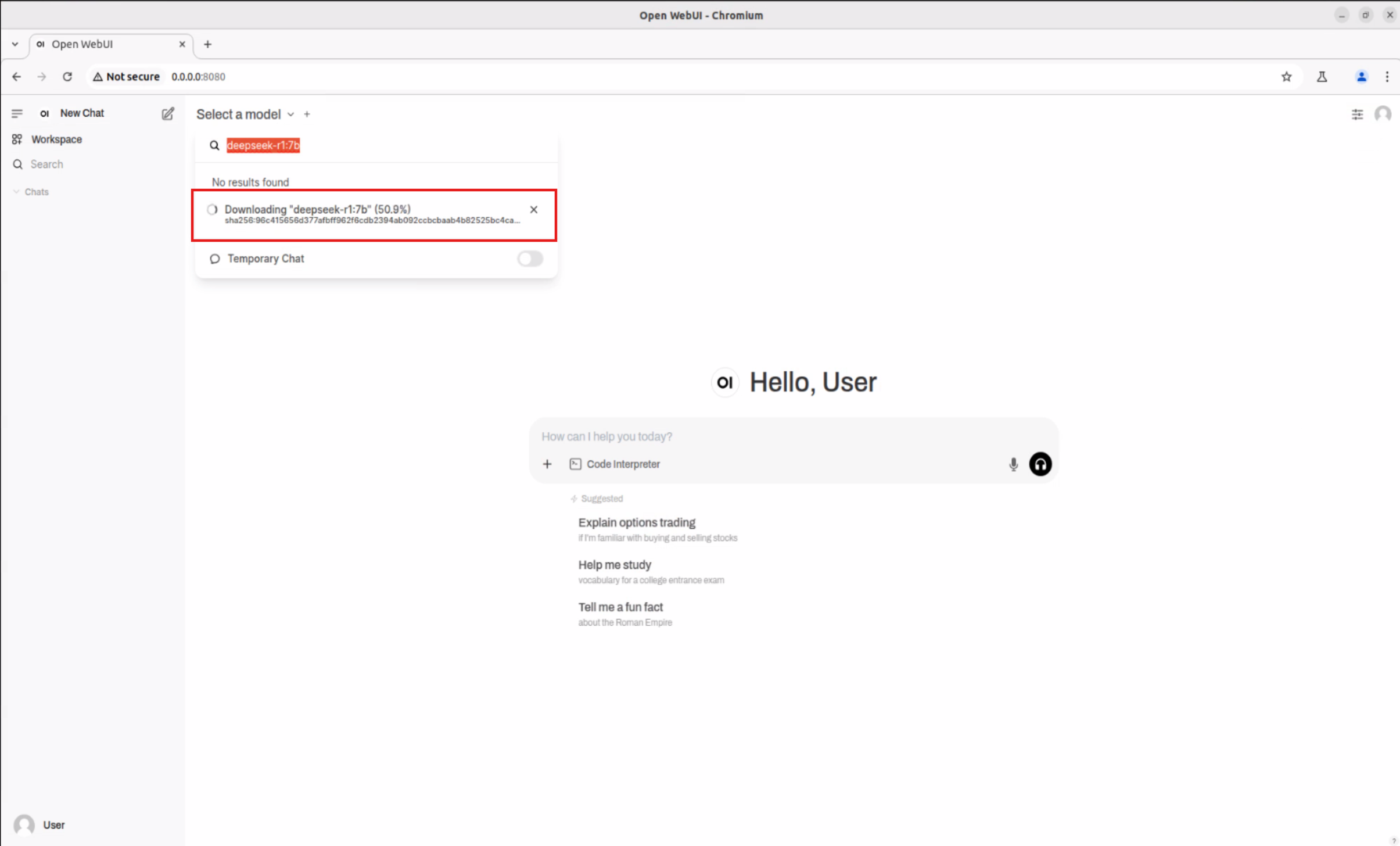
Once selected, the system will prompt you to download the model directly from Ollama.
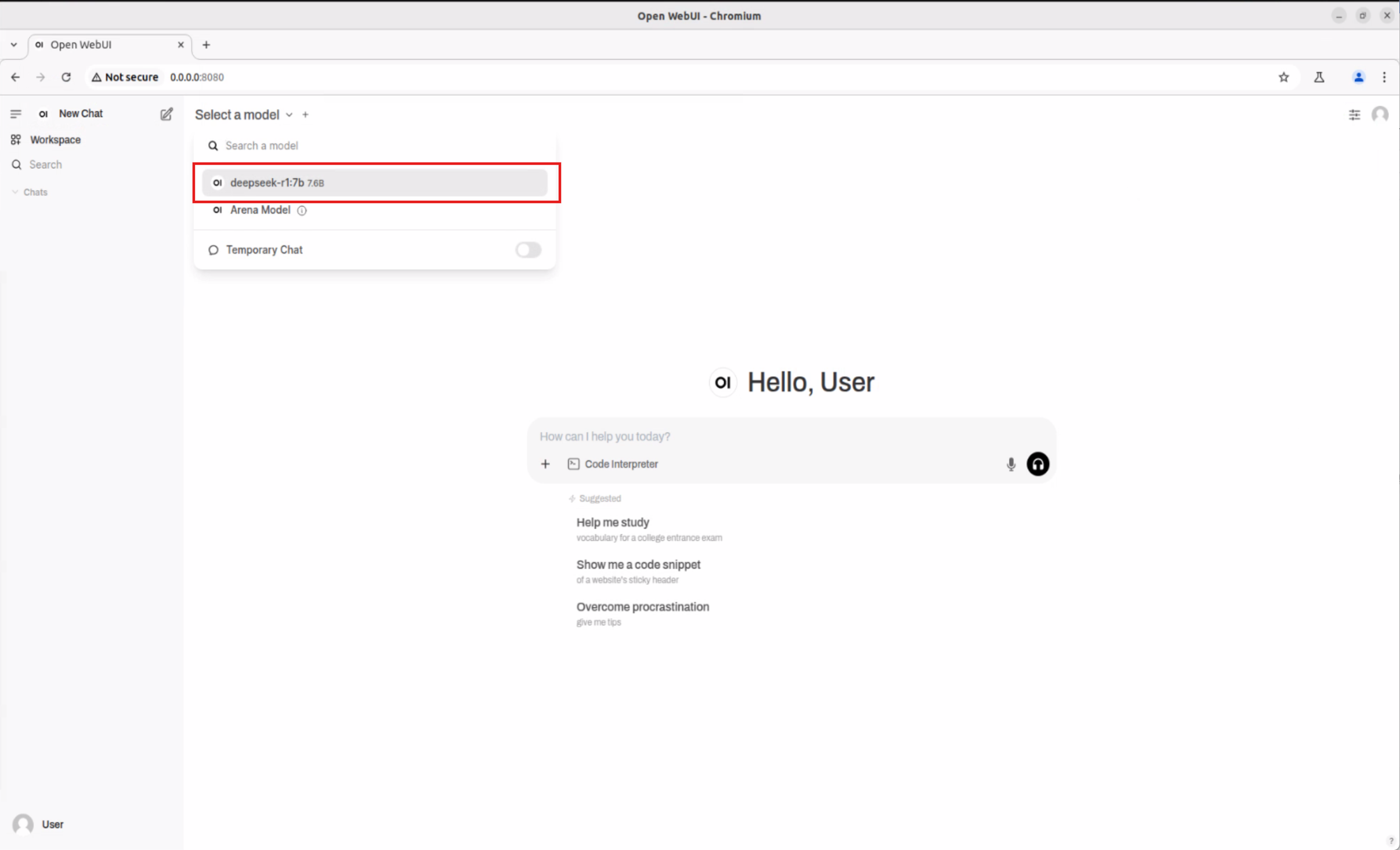
After the download is complete, select the newly downloaded model from the list. In our example, it is the deepseek-r1:7b model.
Step 4. Start Interacting with the Model #
Once the desired model is selected, you can now start interacting with the model just like any other LLM chatbot.
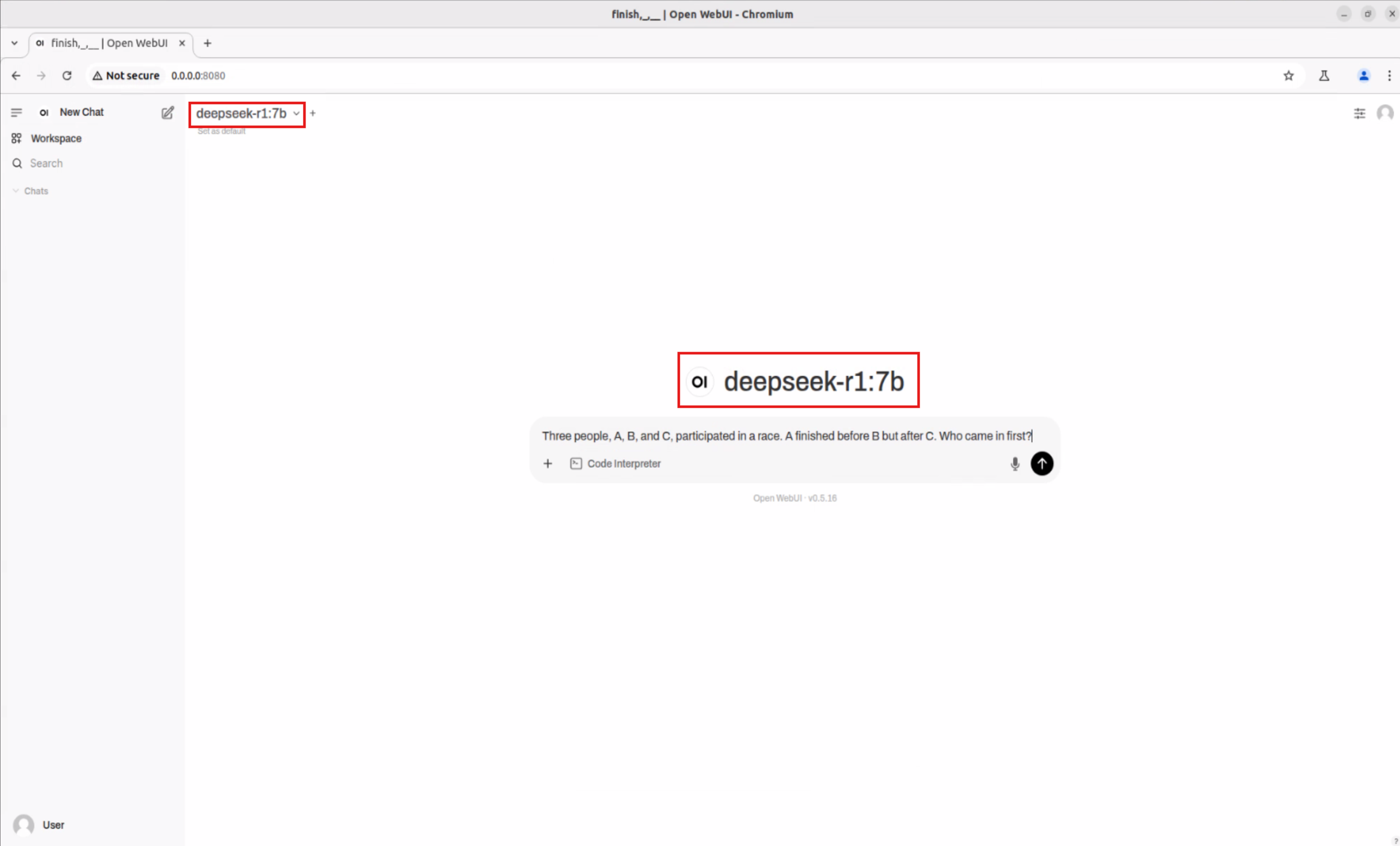
Download the Qwen2.5-Math:7b Model #
Refer to Step 3 ~ Step 4
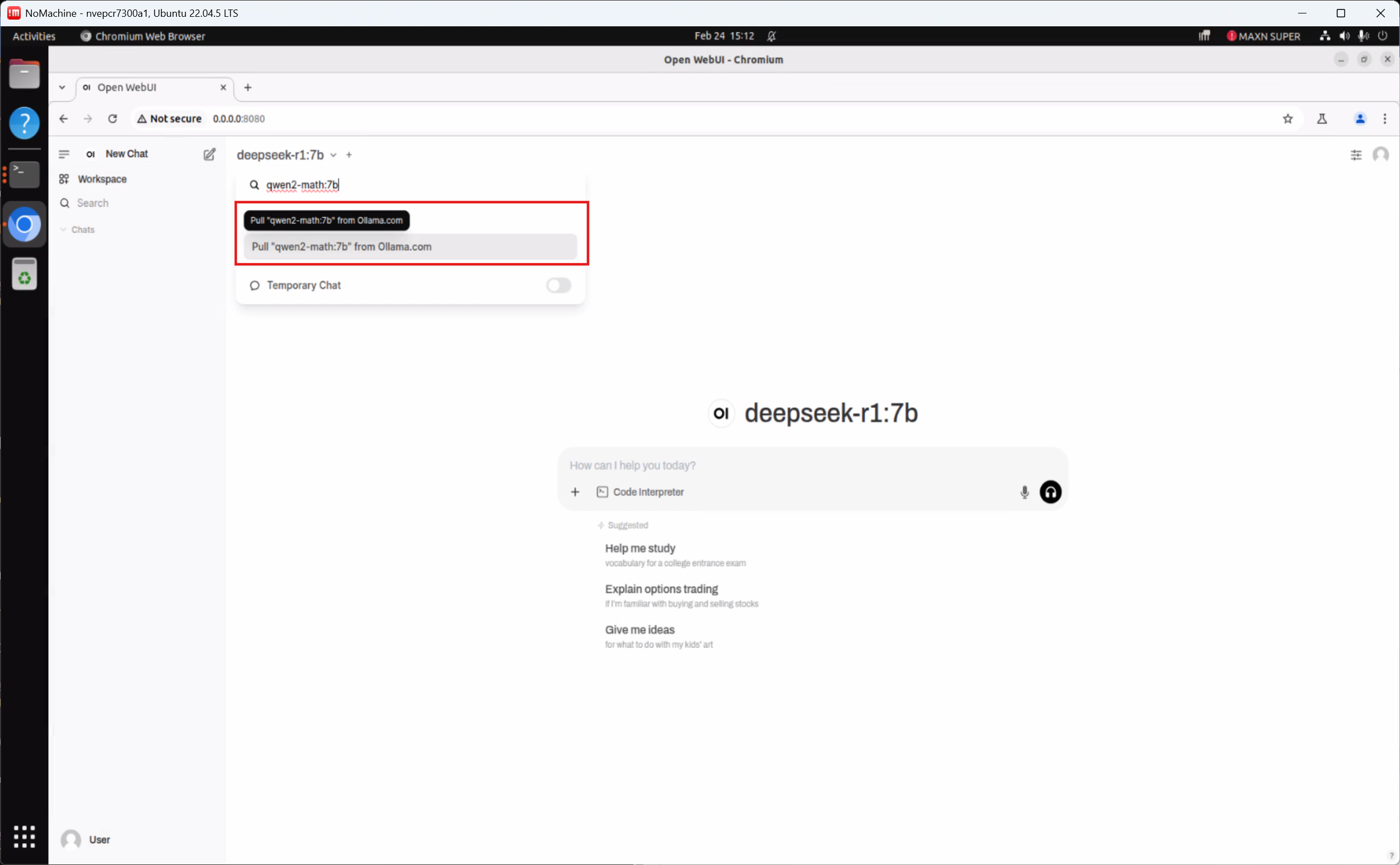
Switch to the Qwen2.5-Math:7b model
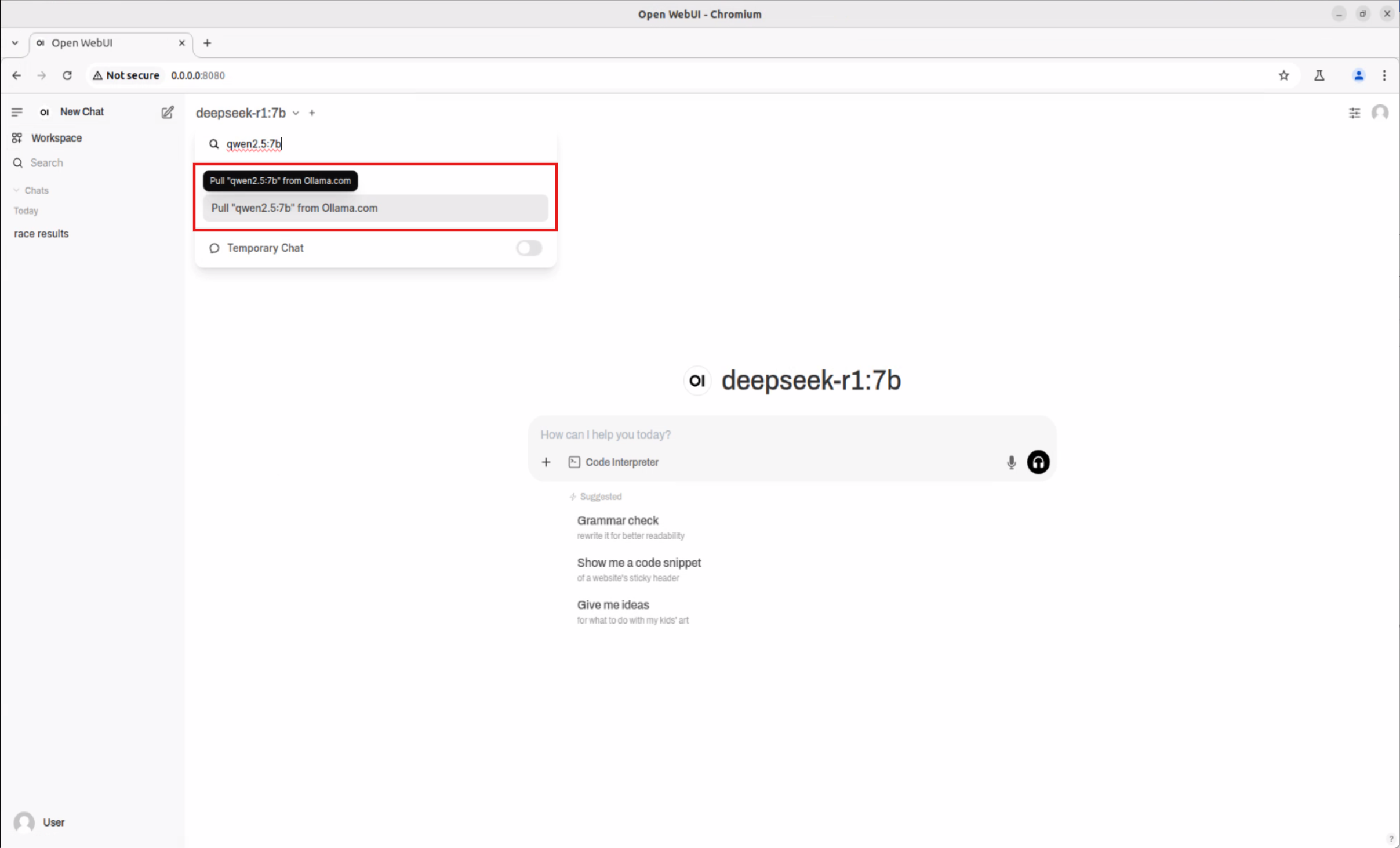
Download the Qwen2.5:7b Model #
Refer to Step 3 ~ Step 4
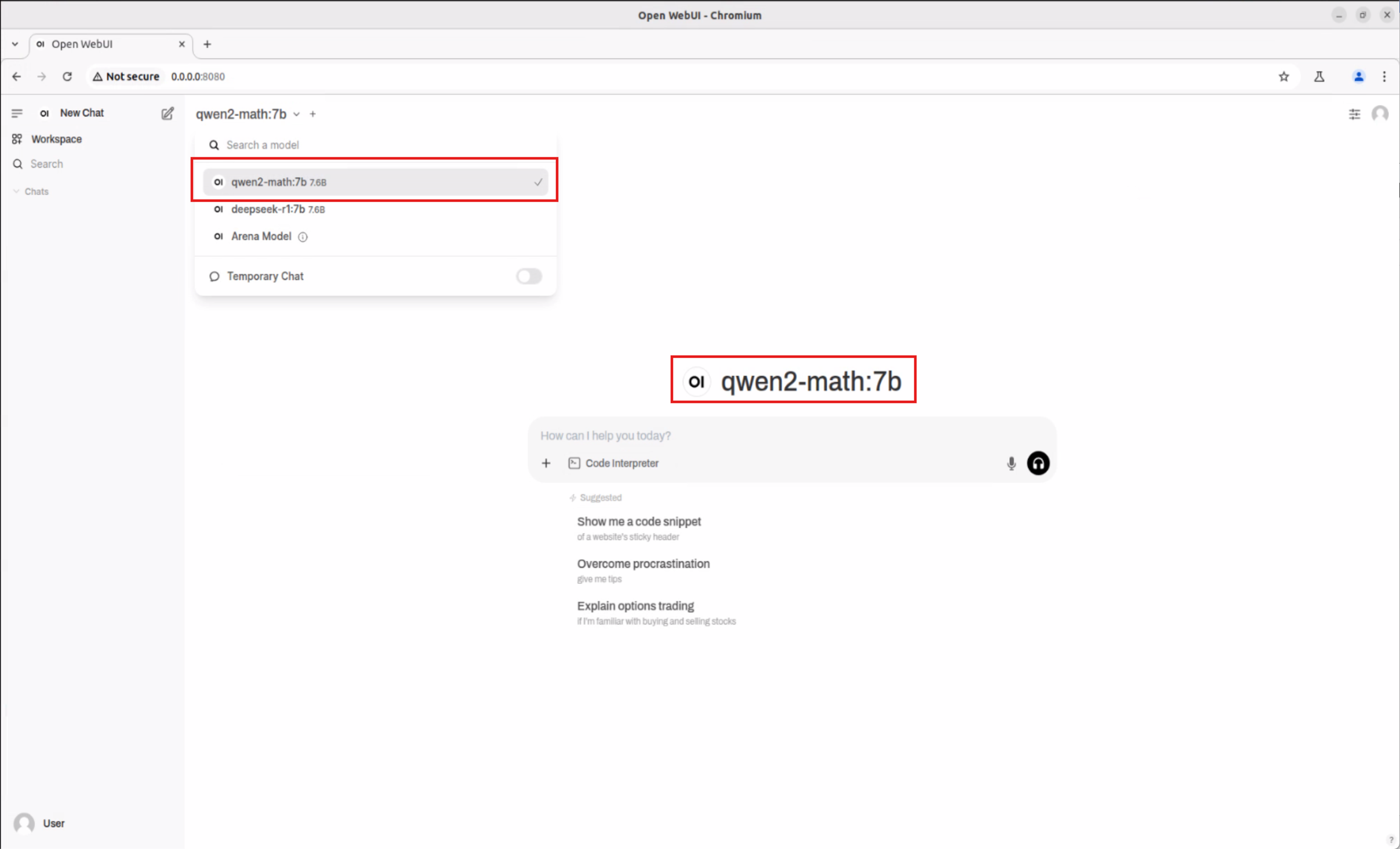
Switch to the Qwen2.5:7b model
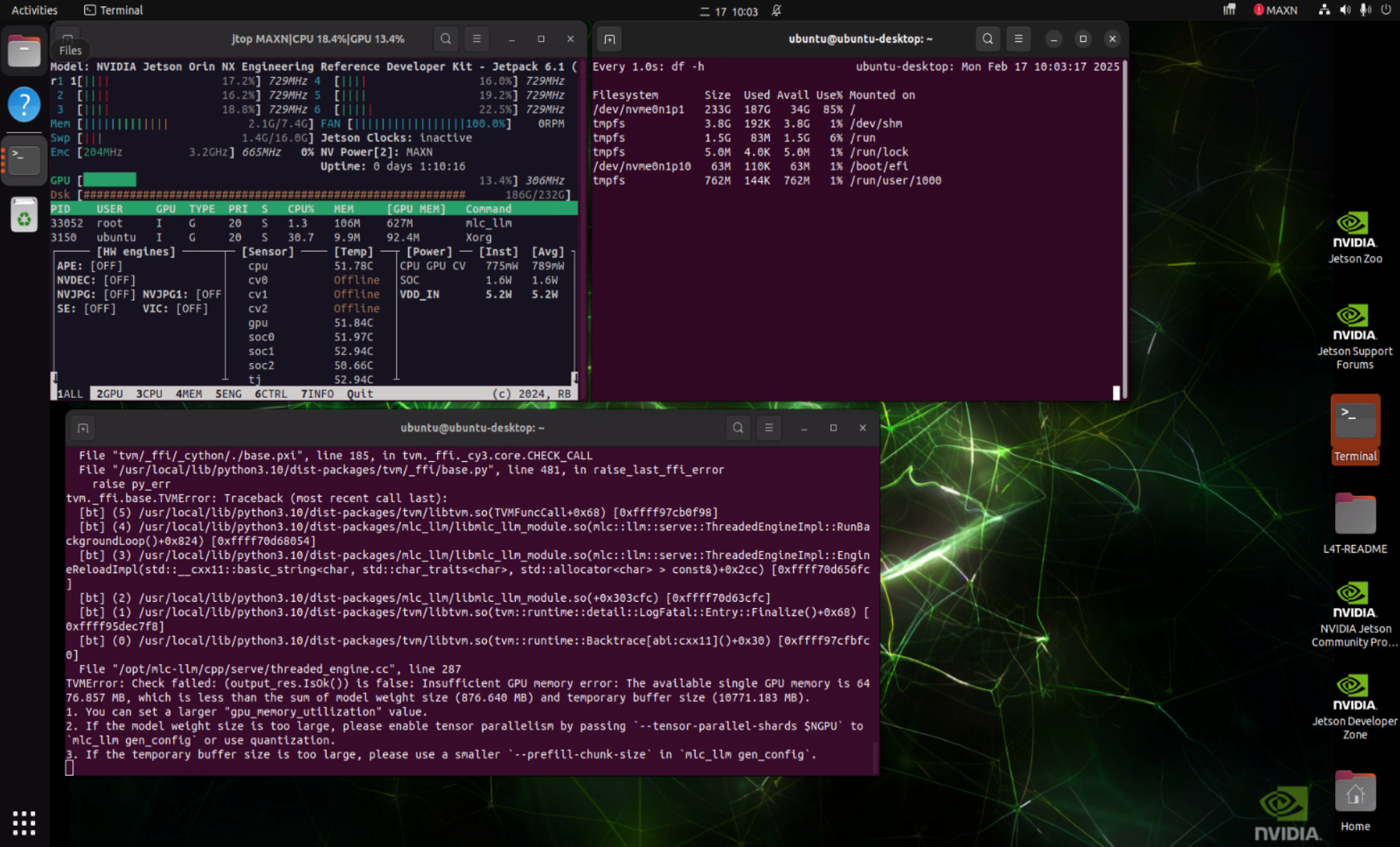
Experiment Side Note:
During the experiment, we also attempted to run the Qwen architecture model using the MLC inference framework but encountered an error. We have consulted NVIDIA official support regarding this part. This also illustrates that on the path of exploring new technologies, there will always be challenges to overcome, and Advantech’s engineering team is actively working with partners to solve these issues and ensure the maturity and stability of the technology.
Experiment Results and Application Outlook #
This experiment successfully demonstrated the feasibility of running sLLM models like DeepSeek R1 on Advantech’s edge platforms based on NVIDIA Jetson Orin!
What does this mean?
- Powerful Edge AI Capabilities: Our platform can not only handle traditional computer vision tasks but now also execute sLLMs with language understanding and generation capabilities, significantly expanding the scope of edge AI applications.
- Support for More Diverse Models: In addition to DeepSeek R1, we also successfully tested the Qwen series models, demonstrating the platform’s good compatibility with different sLLM architectures.
- Opening the Door to Innovative Applications: Imagine in a smart factory, robotic arms can directly understand natural language commands; in retail scenarios, self-service kiosks can provide more intelligent interactions; in the medical field, edge devices can perform preliminary voice medical record recording and analysis. All of these become possible because of sLLMs running at the edge.
- Advantech’s Continuous R&D Strength: This experiment once again proves Advantech’s active investment and R&D capabilities in the field of edge AI. We continuously explore the latest AI technologies and integrate them into our reliable, high-performance hardware platforms to provide leading solutions for our customers.
Compared to the traditional approach of relying entirely on the cloud for LLMs, running sLLMs on Advantech’s edge platforms offers significant advantages: reduced latency, enhanced data privacy, decreased network dependency, and potentially lower long-term operating costs.
Conclusion and Future Outlook #
This experiment of running sLLMs on the Jetson Orin platform is an important step for Advantech in the field of edge AI. It not only verifies the technical feasibility but also opens up infinite possibilities for future innovative applications.
Advantech will continue to invest resources to deeply research how to optimize the performance of sLLMs on edge devices, explore more advanced models, and integrate these capabilities into our products and solutions. We believe that through the close integration of software and hardware and continuous innovation, Advantech will be able to assist customers across various industries in deploying smarter and more powerful AI applications at the edge.
If you are interested in running sLLMs or other edge AI applications on Advantech platforms, please feel free to contact our AE or sales team to explore the infinite potential of edge AI together!