Hello everyone! We are the tech explorers at Advantech. Today, we want to chat about a very cool topic: What changes will it bring to our world when Artificial Intelligence (AI) learns to “tell stories from images” just like humans do?
Imagine if a machine could not only recognize a cat in a photo but also tell you, “This is a lazy orange cat dozing by a sun-drenched window.” Sounds amazing, right? This is the magic of the star of our show today—Vision Language Models (VLMs)!
At Advantech, we don’t just follow the latest technologies; we’re passionate about implementing them in real-world applications. Recently, our engineering team conducted an interesting experiment to see if these intelligent VLMs can run smoothly on compact edge computing devices. Ready? Let’s dive into the evolution of AI vision technology and see how Advantech is leading innovation in this wave!
From “Seeing” to “Understanding”: The Evolution of AI Vision Technology #
Before VLMs emerged, we had Traditional Computer Vision. You can think of it as the “predecessor” of AI vision technology.
Traditional Computer Vision: The High-Achiever Laying the Foundation #
Traditional computer vision enabled machines to “see.” Through meticulously designed algorithms by engineers, machines could:
- Image Classification: Determining if an image contains a cat or a dog.
- Object Detection: Drawing bounding boxes around all cars and pedestrians in an image (the well-known YOLO is a prime example in this field!).
- Image Segmentation: Precisely outlining the contours of each object in an image.
These techniques are incredibly powerful and have made significant contributions in areas such as quality control, security surveillance, and medical image analysis. They are generally computationally efficient and require relatively less data.
But traditional computer vision has its limitations:
- Requires “Expert Guidance”: Heavily relies on engineers’ experience to design features, offering less flexibility for adjustments.
- Limited Understanding: Struggles to comprehend complex scenes or the relationship between images and text. It can recognize a “car” but finds it difficult to describe “a red sports car speeding on a racetrack.”
This is where smarter VLMs, capable of understanding context, come into play!
Vision Language Models (VLMs): The Linguists Who Tell Stories from Images #
VLMs are the rising stars of the AI world. Their key characteristic is the ability to simultaneously understand both “images” and “text.” It’s like giving AI both eyes and a mouth, enabling it not just to see, but also to speak and comprehend!
What can VLMs do?
- Image Captioning: Automatically generating detailed text descriptions for images.
- Visual Question Answering (VQA): You can ask the AI questions about an image, like “How many people in the picture are wearing hats?”, and it can answer based on the visual content.
- Image-Text Matching: Determining if a piece of text description corresponds to a given image.
Representatives of the VLM family include OpenAI’s CLIP, Salesforce’s BLIP, and VILA, the focus of our experiment. They typically use a technique called Vision Transformer (ViT) to understand image content more comprehensively, much like how humans perceive both details and the overall scene simultaneously.
Advantages of VLMs:
- Strong Learning Ability: Can learn autonomously from vast amounts of image-text data without needing manually designed features.
- Deeper Understanding: Can grasp the semantics and context of images, going beyond simple object recognition.
- Broader Applicability: Possess immense potential in areas like visual search, intelligent customer service, and content creation.
A Quick Comparison:
| Feature | Traditional Computer Vision (e.g., YOLO) | Vision Language Model (VLM) |
|---|---|---|
| Core Capability | Object Detection, Classification | Image-Text Understanding, Generation, Q&A |
| Learning Method | Relies on hand-crafted features + algorithms | End-to-end learning from large image-text datasets |
| Understanding Depth | Focuses on visual patterns | Understands visual + textual semantics, context |
| Flexibility | Task-specific | Highly adaptable, allows natural language interaction |
| Strengths | Fast, efficient for specific tasks | Zero-shot learning, complex scene understanding |
Advantech Labs: Bringing VLMs to the “Edge”! #
VLMs are powerful, but they typically involve large models requiring significant computational resources. However, many application scenarios, such as real-time factory monitoring or environmental perception for autonomous vehicles, necessitate computation at the “edge,” close to the data source, to achieve low latency, high efficiency, and data privacy.
This presents a challenge: Can we smoothly run these intelligent VLMs on compact, resource-constrained edge devices?
This was the core objective of the experiment conducted by Advantech engineers! We selected:
- Model: VILA 1.5-3b (a relatively lightweight yet powerful VLM)
- Platform: NVIDIA Jetson Orin Nano Super 8GB (a high-performance edge computing platform commonly used by Advantech)
Experiment Highlights:
Our engineers, like experienced tuners, meticulously worked to get VILA running on the Jetson Orin Nano:
- Deployment Challenge: We found that even the 3B parameter VILA model was quite demanding for the 8GB memory of the Orin Nano. It was like trying to fit large furniture into a small room – requiring some clever techniques.
- Smart Optimization - MLC Shines: We utilized the MLC (Machine Learning Compiler) as our secret weapon. MLC enables model quantization, which you can think of as compressing the model’s “size.” For example, representing numbers that originally required more storage space in a more concise format (like 4-bit integers). This reduces the model’s memory footprint and speeds up computation! This is crucial for resource-constrained edge devices.
- Resource Management Techniques: The engineers also employed several methods to “squeeze out” more memory space, such as:
- Setting up virtual memory (Swap Memory).
- Adjusting the model’s “context length” and “max new tokens” (output length).
- Secret Weapon - JetPack Super Mode: We also leveraged the “Super Mode” available in the NVIDIA JetPack 6.2 SDK. This acts like a performance booster for the Orin Nano, further enhancing AI inference capabilities!
Experimental Results: Success!
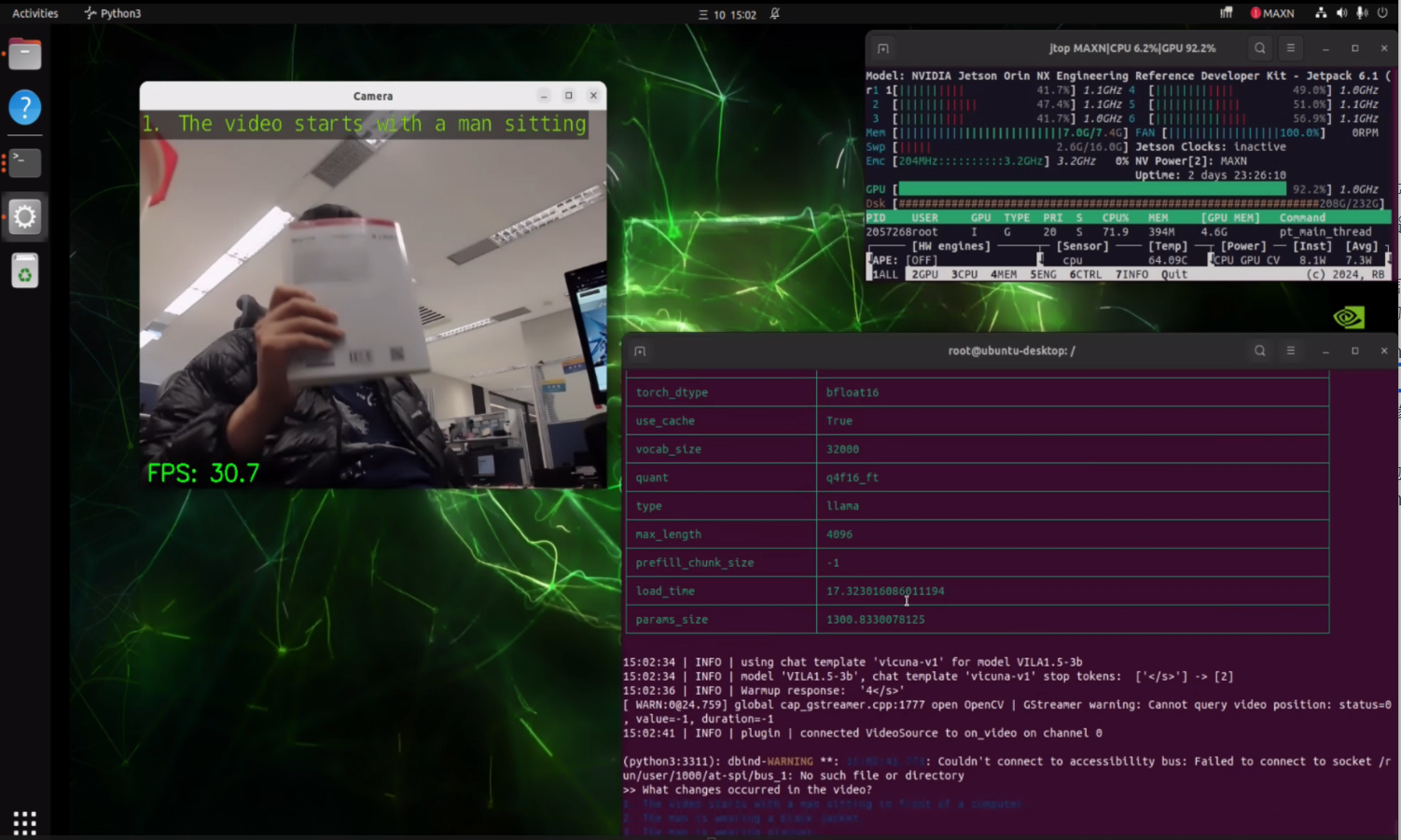
After significant effort, we demonstrated that running VILA 1.5-3b on the NVIDIA Jetson Orin Nano Super 8GB is entirely feasible! This signifies that we can deploy more intelligent AI applications capable of understanding complex scenarios on Advantech’s edge computing platforms in the future. This achievement not only showcases Advantech’s technical prowess in the edge AI domain but also highlights our R&D spirit of continuous exploration and overcoming challenges!
VLMs + Edge Computing = Infinite Future Possibilities #
This successful experiment opens up a world of possibilities for VLM applications at the edge across various industries. Consider these examples:
- Smart Retail: Future store assistants could not only scan barcodes but also understand product photos taken by customers, instantly providing relevant information or recommending similar items. In-store cameras could do more than just count foot traffic; they could understand customer behavior to optimize the shopping experience.
- Traditional CV: Shelf inventory monitoring, foot traffic heatmaps.
- VLM Upgrade: Visual product search, smart recommendations based on preferences, chatbots answering customer questions based on images.
- Smart Healthcare: AI could not only assist doctors in interpreting X-rays but also automatically generate preliminary imaging reports or answer physician questions about specific image regions, improving diagnostic efficiency.
- Traditional CV: Anomaly detection in images, tumor segmentation.
- VLM Upgrade: Automated radiology report generation, visual question answering on images, remote monitoring combining visual data and metrics.
- Smart Manufacturing: Quality inspection could go beyond visual appearance, incorporating text from product specifications to identify subtler defects. AI could understand CAD designs and automatically annotate features. Safety monitoring could integrate safety regulation text for more accurate compliance checks.
- Traditional CV: Defect detection, equipment monitoring, PPE compliance checks.
- VLM Upgrade: Complex defect identification integrating specifications, CAD feature recognition, compliance monitoring against safety regulations.
- Smart Security: Surveillance systems could not only detect intrusions but also understand complex scenes and behaviors, providing more comprehensive situational analysis by combining visual data with text reports, improving response speed and accuracy.
- Traditional CV: Intrusion detection, facial recognition, object tracking.
- VLM Upgrade: Context-aware threat detection, complex behavior analysis, integrated visual-textual situational awareness.
Industry Application Comparison:
| Industry Sector | Traditional Computer Vision (CV) Applications | Vision Language Model (VLM) Applications |
|---|---|---|
| Retail | Real-time shelf monitoring & predictive inventory management | Visual search (find products via images) |
| Customer flow analysis via retail heatmaps | Recommendations combining natural language understanding | |
| Product recognition & fast checkout in unmanned stores | Chatbots answering product questions based on images | |
| Product placement verification & compliance | Automatic tagging of product information in images | |
| Healthcare | X-ray, MRI, CT image analysis | Automated generation of radiology reports |
| Early detection of subtle lesions | Visual question answering & region annotation | |
| Tumor segmentation & surgical assistance | Remote monitoring combining visual appearance & device data | |
| Analyzing video to monitor vital signs | Interactive health assistants combining images and text | |
| Manufacturing | Production line defect & quality inspection | Automated defect identification combining images & specs |
| Equipment monitoring & predictive maintenance | Interpreting CAD drawings & auto-annotating design features | |
| Personal Protective Equipment (PPE) checks | Analyzing images against safety regulations for compliance checks | |
| Robot monitoring & automated line integration | ||
| Inventory management & monitoring | ||
| Security & Surveillance | Intrusion detection & unauthorized activity identification | Enhanced monitoring judgment by analyzing visual & contextual text |
| Facial recognition for access control | Understanding complex interactions & describing them in natural language | |
| Object detection & tracking | Integrating camera feeds with textual knowledge for better environmental understanding | |
| Traffic analysis & event judgment | ||
| License plate recognition & abnormal behavior monitoring |
Conclusion: Embracing the New Vision of AI, Advantech Walks with You #
From traditional computer vision to vision language models, the way AI “sees the world” is undergoing a profound transformation. The advent of VLMs enables machines not only to “see” but also to “understand” and “communicate,” unlocking unprecedented potential for intelligence across all industries.
Advantech’s experiment successfully validated the feasibility of deploying VLMs on edge devices. This is not just a small step technologically, but a significant leap forward in advancing intelligent edge applications. It demonstrates that Advantech not only stays abreast of the latest developments in AI technology but also possesses the robust R&D capabilities to translate cutting-edge innovations into practical applications and overcome engineering hurdles.
Looking ahead, we can expect VLM technology to continue evolving—becoming more powerful, more efficient, and better suited for edge deployment. Advantech remains committed to investing in R&D, exploring further possibilities for VLMs in domains such as the Industrial Internet of Things (IIoT), smart cities, and smart healthcare. We will continue to collaborate with our customers and partners to co-create a smarter, more connected future!